

RAG(Retrieval-AugmentedGeneration)とファインチューニングは、大規模言語モデル(LLM)の性能を向上させるための代表的な手法です。この記事では、それぞれの違い、メリット・デメリット、活用事例を比較し、最適な選択肢をわかりやすく解説します。
RAGとファインチューニング:基本概念の整理
RAG(検索拡張生成)とは?仕組みと特徴
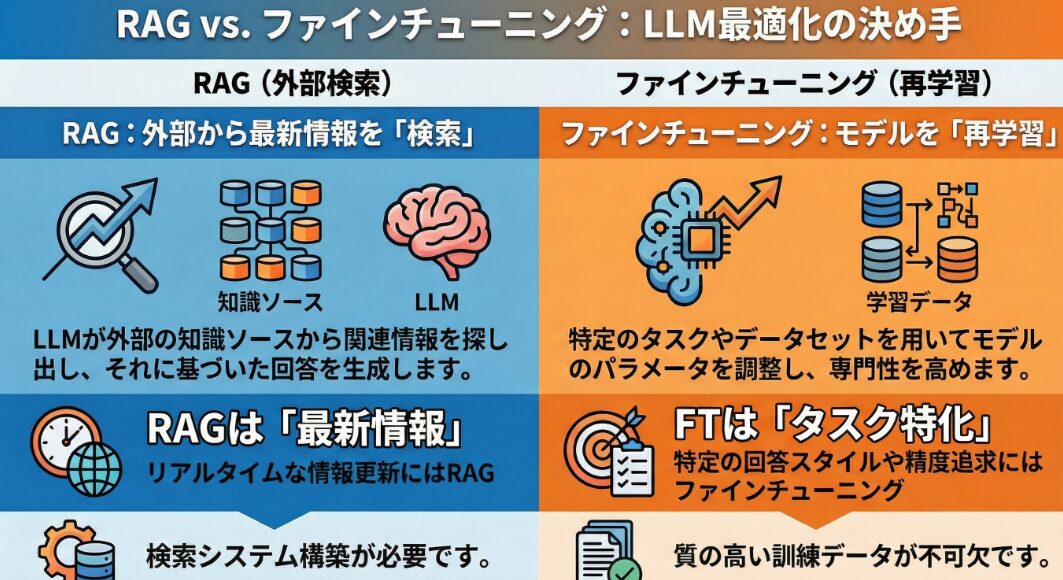
RAG(Retrieval-AugmentedGeneration:検索拡張生成)は、大規模言語モデル(LLM)の性能を向上させるためのアプローチです。具体的には、LLMがテキストを生成する際に、外部の情報源から関連情報を検索し、その検索結果を基にしてテキストを生成します。
この仕組みにより、LLMは自身の学習データに限定されず、最新の情報や特定のドメインに特化した知識を活用できます。RAGの主な特徴は、リアルタイムな情報更新に対応できること、特定の知識領域を容易に組み込めること、そしてモデルの再学習が不要なことです。
RAGは、LLMが持つ知識の限界を克服し、より正確で信頼性の高い回答を生成するための有効な手段として注目されています。例えば、顧客からの問い合わせに対して、製品マニュアルやFAQなどの情報を検索し、それに基づいて回答を生成する、といった活用が考えられます。
RAGは、LLMの応用範囲を広げ、様々な分野でその可能性を最大限に引き出すための重要な技術と言えるでしょう。
ファインチューニングとは?仕組みと特徴
ファインチューニングは、すでに学習済みの大規模言語モデル(LLM)を、特定のタスクやデータセットに合わせて再学習させる手法です。これにより、LLMは特定の分野やタスクにおいて、より高い精度を発揮できるようになります。ファインチューニングのプロセスでは、LLMのパラメータの一部または全部を、新しいデータを用いて調整します。
この調整により、LLMは特定のタスクに対する理解を深め、より適切な応答を生成できるようになります。ファインチューニングの主な特徴は、比較的小規模なデータセットでも効果を発揮しやすいこと、特定のタスクに特化したモデルを効率的に作成できること、そしてLLMの潜在能力を最大限に引き出せることです。
例えば、顧客サポートに特化したチャットボットを開発する場合、既存のLLMを顧客からの問い合わせデータでファインチューニングすることで、より的確な回答を生成できるチャットボットを開発できます。
ファインチューニングは、LLMを特定の目的に合わせて最適化し、その性能を最大限に引き出すための重要な技術です。
RAGとファインチューニングの主な違い
RAG(検索拡張生成)とファインチューニングは、どちらも大規模言語モデル(LLM)の性能を向上させるための手法ですが、そのアプローチは大きく異なります。RAGは、LLMがテキストを生成する際に、外部の知識ソースから関連情報を検索し、その情報を基にテキストを生成します。
一方、ファインチューニングは、既存のLLMのパラメータを、特定のタスクやデータセットに合わせて調整する手法です。RAGは、リアルタイムな情報更新に強く、常に最新の情報に基づいて回答を生成できます。また、特定のドメイン知識を容易に組み込むことができます。
これに対し、ファインチューニングは、特定のタスクに特化させるのに適しており、そのタスクにおいて高い精度を発揮できます。RAGは、外部知識を利用するため、検索システムの構築と維持が必要になります。一方、ファインチューニングは、学習データの準備が必要であり、過学習のリスクも考慮する必要があります。
どちらの手法を選択するかは、プロジェクトの要件や利用可能なリソースによって異なります。リアルタイムな情報更新が必要な場合や、特定のドメイン知識を容易に組み込みたい場合はRAGが適しています。特定のタスクに特化した性能を求める場合は、ファインチューニングが適しています。
RAGとファインチューニング:メリット・デメリット比較
RAGのメリットとデメリット
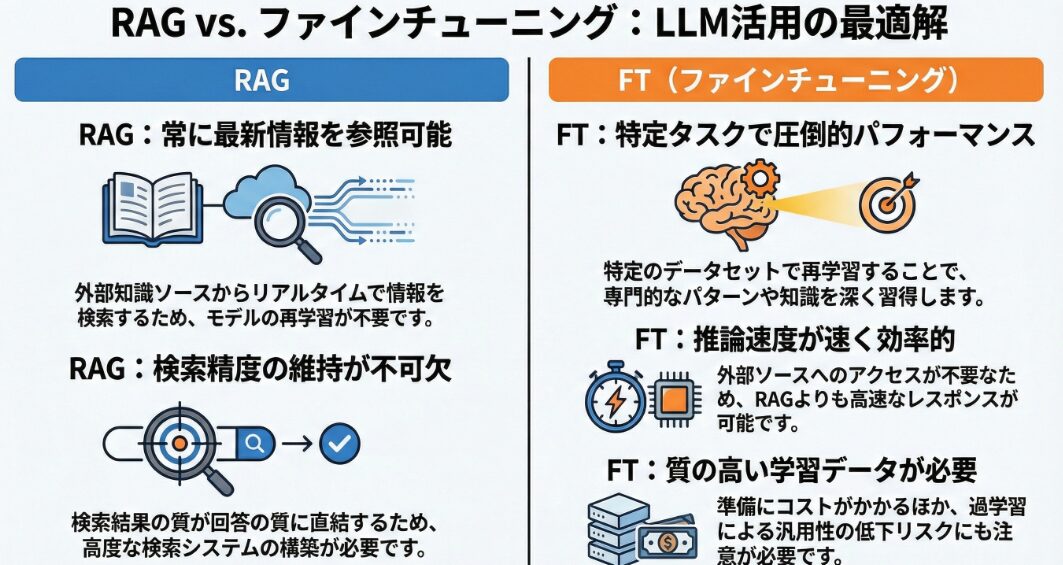
RAG(検索拡張生成)は、その仕組みから様々なメリットとデメリットを有しています。メリットとしては、まず、常に最新の情報に基づいて回答を生成できる点が挙げられます。これは、外部の知識ソースからリアルタイムに情報を検索し、それを基にテキストを生成するためです。
また、特定のドメイン知識を容易に組み込める点も大きなメリットです。特定の分野に特化した知識ベースを構築し、それをRAGに組み込むことで、専門的な質問にも的確に回答できるようになります。さらに、モデルの再学習が不要な点もメリットとして挙げられます。LLM自体を再学習させる必要がないため、学習コストを抑えられます。
一方、デメリットとしては、検索システムの構築と維持が必要な点が挙げられます。検索システムの構築には、それなりの技術力とコストがかかります。また、検索結果の品質に左右される点もデメリットです。検索結果が不正確であったり、関連性が低い場合、生成されるテキストの品質も低下してしまいます。
RAGを導入する際には、これらのメリットとデメリットを十分に理解し、自社のニーズに合ったシステム構築を行う必要があります。
ファインチューニングのメリットとデメリット
ファインチューニングは、LLMの性能を向上させる強力な手法ですが、メリットとデメリットが存在します。メリットとして、特定のタスクに対する性能を大幅に向上させられる点が挙げられます。これは、モデルを特定のデータセットで再学習させることで、そのタスクに特化した知識やパターンを習得させられるためです。
また、RAG(検索拡張生成)と比較して、推論速度が速いというメリットもあります。ファインチューニングされたモデルは、外部の知識ソースにアクセスする必要がないため、高速に回答を生成できます。しかし、ファインチューニングにはデメリットも存在します。まず、学習データの準備が必要な点が挙げられます。
質の高い学習データを準備するには、それなりの労力とコストがかかります。また、過学習のリスクも考慮する必要があります。学習データに偏りがあると、モデルがそのデータに過剰に適合してしまい、汎用性が低下してしまう可能性があります。
さらに、ファインチューニングによって、モデルの汎用性が低下する可能性もあります。特定のタスクに特化させるほど、他のタスクに対する性能が低下する場合があります。ファインチューニングを行う際には、これらのメリットとデメリットを十分に理解し、慎重に検討する必要があります。
どちらを選ぶべきか?選択のポイント
リアルタイム性と情報更新の必要性
RAG(検索拡張生成)とファインチューニングのどちらを選択するかを検討する際、まず考慮すべきは、リアルタイム性と情報更新の必要性です。常に最新の情報に基づいて回答する必要がある場合は、RAGが適しています。RAGは、外部の知識ソースからリアルタイムに情報を検索し、それを基にテキストを生成するため、常に最新の情報に対応できます。
例えば、ニュース記事の要約や、株価の変動に関する質問など、リアルタイムな情報が重要なタスクには、RAGが有効です。一方、特定の時点での知識で十分な場合は、ファインチューニングでも対応可能です。例えば、歴史的な出来事に関する質問や、特定の専門分野の知識に関する質問など、情報が更新される必要がないタスクには、ファインチューニングが適しています。
ただし、ファインチューニングの場合、情報が更新された際には、再度モデルを学習させる必要があります。そのため、情報更新の頻度が高い場合は、RAGの方が効率的と言えるでしょう。どちらの手法を選択するかは、タスクの性質と情報更新の頻度を考慮して決定する必要があります。
タスクの専門性と特化性
RAG(検索拡張生成)とファインチューニングの選択において、タスクの専門性と特化性は重要な判断基準となります。特定のタスクに特化した性能を求める場合は、ファインチューニングが適しています。ファインチューニングは、既存のLLMを特定のデータセットで再学習させることで、そのタスクに特化した知識やパターンを習得させることができます。
例えば、医療分野の専門用語を理解させたり、特定の文体を模倣させたりすることが可能です。これにより、そのタスクにおいて、より高い精度と効率を実現できます。一方、汎用的なタスクに対応する必要がある場合は、RAGが適しています。RAGは、外部の知識ソースから関連情報を検索し、それを基にテキストを生成するため、幅広い分野の質問に対応できます。
例えば、様々なジャンルの質問に答えたり、複数の情報源から情報を統合したりすることが可能です。ただし、RAGの場合、検索システムの品質が性能に大きく影響するため、適切な検索システムを構築する必要があります。どちらの手法を選択するかは、タスクの範囲と求める性能を考慮して決定する必要があります。
リソースとコスト
RAG(検索拡張生成)とファインチューニングを選択する際には、リソースとコストも重要な考慮事項です。RAGは、検索システムの構築・維持コストがかかる一方、ファインチューニングは学習データの準備コストがかかります。RAGの場合、外部の知識ソースから情報を検索するためのシステムを構築し、維持する必要があります。
これには、検索エンジンの導入、インデックスの作成、データの更新などが含まれます。また、検索システムの性能を維持するためには、継続的なメンテナンスが必要です。一方、ファインチューニングの場合、質の高い学習データを準備する必要があります。学習データの収集、クリーニング、アノテーションなどには、それなりの労力とコストがかかります。
また、学習データの量や質によって、モデルの性能が大きく左右されるため、十分な注意が必要です。どちらがより効率的かは、プロジェクトの規模や利用可能なリソースによって異なります。小規模なプロジェクトや、利用可能な学習データが少ない場合は、RAGの方が適しているかもしれません。
一方、大規模なプロジェクトや、質の高い学習データが豊富にある場合は、ファインチューニングの方が適しているかもしれません。リソースとコストを総合的に評価し、最適な手法を選択することが重要です。
事例紹介:RAGとファインチューニングの活用
RAGの活用事例:IBM Watson Discovery
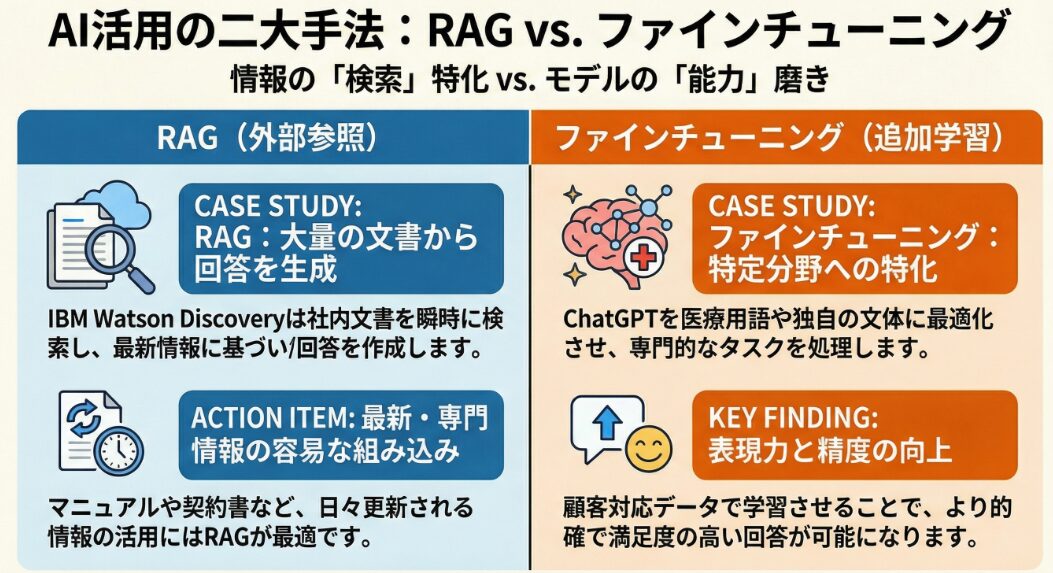
RAG(検索拡張生成)の活用事例として、IBM Watson Discoveryが挙げられます。IBM WatsonDiscoveryは、RAGを活用して、大量のドキュメントから必要な情報を迅速に検索し、回答を生成するソリューションです。企業内に蓄積された様々なドキュメント(契約書、技術文書、顧客対応履歴など)から、質問に対する回答を効率的に見つけ出すことができます。
例えば、顧客からの問い合わせに対して、関連するFAQや製品マニュアルを検索し、それに基づいて回答を生成するといった活用が可能です。また、ナレッジマネジメントの分野でも活用されており、従業員が求める情報を迅速に見つけ出し、業務効率を向上させることに貢献しています。IBMWatsonDiscoveryは、RAGのメリットである、最新の情報に基づいた回答生成と、特定のドメイン知識の容易な組み込みを活かした事例と言えるでしょう。
特に、大量のドキュメントを扱う企業にとって、RAGは非常に有効なソリューションとなり得ます。IBMWatson Discoveryの事例は、RAGが様々な分野で活用できる可能性を示唆しています。
ファインチューニングの活用事例:ChatGPTのカスタマイズ
ファインチューニングの活用事例として、ChatGPTのカスタマイズが挙げられます。ChatGPTは、OpenAIが開発した大規模言語モデルであり、様々なタスクに対応できますが、特定の業界やタスクに合わせてファインチューニングすることで、より専門的な知識や表現を習得させることができます。例えば、医療分野の専門用語を理解させたり、特定の文体を模倣させたりすることが可能です。
これにより、医療分野に特化したチャットボットや、特定の作家の文体を模倣した文章生成など、様々な応用が考えられます。ある企業では、ChatGPTを顧客サポートに特化させるために、顧客からの問い合わせデータでファインチューニングしました。その結果、ChatGPTは顧客からの問い合わせに対して、より的確な回答を生成できるようになり、顧客満足度が向上しました。
このように、ファインチューニングは、LLMを特定の目的に合わせて最適化し、その性能を最大限に引き出すための有効な手段です。ChatGPTのカスタマイズ事例は、ファインチューニングが様々な分野で活用できる可能性を示唆しています。
まとめ:RAGとファインチューニングの最適な使い分け
RAG(検索拡張生成)とファインチューニングは、それぞれ異なる特徴を持つ強力な手法であり、大規模言語モデル(LLM)の性能を最大限に引き出すための重要なツールです。RAGは、リアルタイムな情報更新が必要な場合や、特定のドメイン知識を容易に組み込みたい場合に適しています。
一方、ファインチューニングは、特定のタスクに特化した性能を求める場合に適しています。RAGを選択する際には、検索システムの構築・維持コスト、検索結果の品質などを考慮する必要があります。ファインチューニングを選択する際には、学習データの準備コスト、過学習のリスク、モデルの汎用性などを考慮する必要があります。
プロジェクトの要件、利用可能なリソース、そして求める性能を総合的に考慮し、最適な手法を選択することが重要です。RAGとファインチューニングを組み合わせることで、それぞれのメリットを活かし、より高度なタスクに対応することも可能です。例えば、RAGで得られた情報を基に、ファインチューニングされたモデルがテキストを生成する、といった連携が考えられます。
RAGとファインチューニングは、LLMの可能性を広げるための重要な技術であり、今後ますますその活用が期待されます。これらの技術を理解し、適切に使い分けることで、LLMの潜在能力を最大限に引き出すことができるでしょう。










