

RAG(Retrieval-AugmentedGeneration、検索拡張生成)は、LLM(大規模言語モデル)の精度と信頼性を向上させるための重要な技術です。この記事では、RAGの基本的な仕組みから、そのメリット、活用事例、構築方法までをわかりやすく解説します。
RAG(検索拡張生成)とは?

RAGの基本概念
RAG(検索拡張生成)は、大規模言語モデル(LLM)が持つ知識の限界を補い、より正確で信頼性の高い回答を生成するための技術です。外部の知識ソースから関連情報を検索し、その情報を基にLLMが回答を生成することで、ハルシネーション(誤った情報の生成)を抑制し、最新の情報に基づいた回答を提供できます。
RAG(検索拡張生成)は、大規模言語モデル(LLM)が抱える課題、特に知識の限界と不確実な情報生成(ハルシネーション)に対処するための革新的なアプローチです。LLMは膨大な量のテキストデータで学習しますが、その知識は学習データに限定され、最新情報や特定のドメインに関する深い知識が不足する場合があります。
RAGは、このようなLLMの弱点を補完し、より信頼性が高く、コンテキストに即した回答を提供することを目的としています。
具体的には、質問やタスクが与えられた際に、LLMはまず外部の知識源(例えば、ウェブサイト、データベース、ドキュメントストアなど)から関連情報を検索します。
次に、検索された情報をLLMに入力として与え、それに基づいて回答を生成させます。このプロセスにより、LLMは自身の学習データにない情報や最新の情報を利用できるようになり、より正確で信頼性の高い回答を生成することが可能になります。RAGは、情報検索と自然言語生成の技術を組み合わせることで、LLMの能力を拡張し、様々な分野での応用を可能にする重要な技術です。
RAGの仕組み

RAGは、質問応答システムにおいて、質問に基づいて関連する情報を外部のデータベースから検索し、その情報をLLMに提供することで、より正確な回答を生成します。このプロセスは、質問のエンコード、関連情報の検索、情報の統合と文脈理解、回答の最適化というステップで構成されます。
RAG(検索拡張生成)の仕組みは、質問応答システムにおいて、質問に基づいて関連する情報を外部のデータベースから検索し、その情報をLLMに提供することで、より正確な回答を生成するプロセスです。このプロセスは、大きく分けて以下の4つのステップで構成されます。
1.質問のエンコード: ユーザーからの質問を、LLMが理解できる形式に変換します。
具体的には、質問文をベクトルと呼ばれる数値データに変換します。
このベクトルは、質問の意味や意図を表現するものとなります。
2. 関連情報の検索: エンコードされた質問ベクトルに基づいて、外部のデータベースから関連性の高い情報を検索します。
データベースには、テキストデータやドキュメントなどが格納されており、
それぞれがベクトルとして表現されています。質問ベクトルとデータベース内のベクトルとの類似度を計算し、類似度の高い情報を関連情報として抽出します。
3. 情報の統合と文脈理解: 検索された関連情報をLLMに入力として与え、
質問と関連情報の両方を考慮して文脈を理解させます。LLMは、質問と関連情報の間の関係性を分析し、回答に必要な情報を特定します。
4.回答の最適化: LLMは、文脈理解に基づいて回答を生成します。
生成された回答は、質問に対する正確性、適切性、流暢さなどを考慮して最適化されます。必要に応じて、回答を修正したり、情報を追加したりすることで、より質の高い回答を提供します。
これらのステップを通じて、RAGはLLMが持つ知識の限界を補い、より正確で信頼性の高い回答を生成することができます。
RAGとLLMの関係
RAGはLLMの弱点を補完する役割を果たします。LLM単独では学習データに含まれていない情報や最新の情報を扱うことが難しいですが、RAGを組み合わせることで、LLMは常に最新の情報に基づいて回答を生成できます。IDAIコンシェルジュProのようなサービスもRAGの技術を利用しています。
RAG(検索拡張生成)は、大規模言語モデル(LLM)の弱点を補完し、その能力を最大限に引き出すための重要な技術です。
LLM単独では、学習データに含まれていない情報や最新の情報を扱うことが難しく、誤った情報(ハルシネーション)を生成する可能性もあります。
RAGは、このようなLLMの課題を解決するために、外部の知識ソースから関連情報を検索し、LLMに提供することで、
常に最新の情報に基づいて回答を生成できるようにします。具体的には、LLMはRAGによって提供された情報を基に、
質問に対する回答を生成したり、テキストを生成したりします。
これにより、LLMは自身の学習データにない情報や、最新の情報を活用できるようになり、より正確で信頼性の高い結果を提供できます。
RAGは、LLMの知識を拡張し、その適用範囲を広げるための鍵となる技術であり、様々な分野での応用が期待されています。
例えば、顧客サポート、医療診断、金融分析など、正確性と信頼性が求められる分野において、RAGはLLMの価値を大きく向上させることができます。
RAGとLLMは、互いに補完し合う関係にあり、両者を組み合わせることで、より高度な自然言語処理タスクを遂行することが可能になります。
RAGのメリットとデメリット
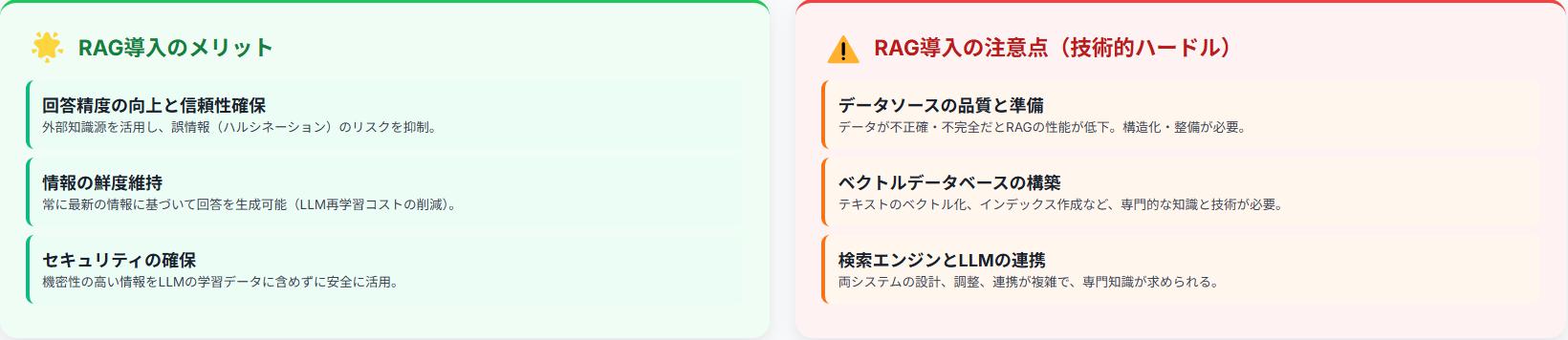
RAG導入のメリット
RAGを導入することで、LLMの回答精度が向上し、より信頼性の高い情報を提供できるようになります。また、常に最新の情報に基づいて回答を生成できるため、情報の鮮度を保つことができます。さらに、機密性の高い情報を外部に公開せずに活用できるため、セキュリティ面でもメリットがあります。
RAG(検索拡張生成)を導入することで、大規模言語モデル(LLM)の回答精度が向上し、より信頼性の高い情報を提供できるようになるというメリットがあります。LLMは、学習データに基づいて回答を生成しますが、学習データには限界があり、最新の情報や特定のドメインに関する深い知識が不足する場合があります。
RAGを導入することで、LLMは外部の知識ソースから関連情報を検索し、その情報を基に回答を生成できるようになります。
これにより、LLMは常に最新の情報に基づいて回答を生成でき、回答の正確性と信頼性を向上させることができます。
また、RAGは、情報の鮮度を保つことができるというメリットもあります。
LLMの学習データは、定期的に更新する必要がありますが、更新には時間とコストがかかります。
RAGを導入することで、LLMは常に最新の情報に基づいて回答を生成できるため、学習データの更新頻度を減らすことができます。
さらに、RAGは、機密性の高い情報を外部に公開せずに活用できるため、セキュリティ面でもメリットがあります。
機密性の高い情報は、LLMの学習データに含めることができませんが、RAGを導入することで、LLMは外部の知識ソースから機密性の高い情報を検索し、その情報を基に回答を生成できるようになります。これにより、機密性の高い情報を安全に活用することができます。
RAG導入の注意点
RAGの導入には、適切なデータソースの準備やベクトルデータベースの構築など、一定の技術的なハードルが存在します。また、検索エンジンの設計やLLMとの連携など、専門的な知識が必要となる場合があります。RAGFlowのようなフレームワークを利用することで、これらの課題を軽減できます。
RAG(検索拡張生成)の導入には、いくつかの注意点があります。
まず、適切なデータソースの準備が不可欠です。RAGは、外部の知識ソースから関連情報を検索するため、データソースの品質と網羅性がRAGの性能に大きく影響します。
データソースが不正確であったり、情報が不足していたりすると、RAGは誤った情報や不完全な情報に基づいて回答を生成してしまう可能性があります。
そのため、データソースの選定と整備には十分な注意が必要です。次に、ベクトルデータベースの構築も重要な課題です。ベクトルデータベースは、テキストデータをベクトルと呼ばれる数値データに変換し、効率的に検索するためのデータベースです。
ベクトルデータベースの構築には、専門的な知識と技術が必要であり、適切な構築方法を選択しないと、検索性能が低下してしまう可能性があります。
また、検索エンジンの設計やLLMとの連携も重要な注意点です。RAGは、検索エンジンとLLMを組み合わせたシステムであるため、両者の連携がうまくいかないと、RAGの性能を最大限に発揮することができません。
検索エンジンの設計やLLMとの連携には、専門的な知識が必要となる場合があります。RAGFlowのようなフレームワークを利用することで、これらの課題を軽減できます。
RAGと他の手法との比較
LLMの性能向上には、RAGの他に、転移学習やファインチューニングといった手法があります。転移学習は、既存の学習済みモデルを別のタスクに適用する手法であり、ファインチューニングは、特定のデータセットでモデルを再学習させる手法です。RAGは、これらの手法とは異なり、外部の知識ソースを活用することで、LLMの知識を拡張します。
大規模言語モデル(LLM)の性能を向上させるためには、RAG(検索拡張生成)以外にも、転移学習やファインチューニングといった手法が存在します。
転移学習は、既存の学習済みモデルを別のタスクに適用する手法であり、例えば、ある言語で学習されたモデルを、別の言語のタスクに適用することができます。
転移学習は、新しいタスクのために大量のデータを収集する必要がないため、効率的な手法として知られています。
一方、ファインチューニングは、特定のデータセットでモデルを再学習させる手法です。
ファインチューニングは、特定のタスクに特化したモデルを構築するために用いられ、高い性能を発揮することができます。
RAGは、これらの手法とは異なり、外部の知識ソースを活用することで、LLMの知識を拡張します。
RAGは、LLMが持つ知識の限界を補い、より正確で信頼性の高い回答を生成するために用いられます。
転移学習やファインチューニングは、モデル自体を修正する手法であるのに対し、RAGは、モデルの知識を外部から補完する手法であるという点で、大きく異なります。それぞれの手法には、メリットとデメリットがあり、タスクの性質や利用可能なデータ量などを考慮して、適切な手法を選択する必要があります。
RAGは、特に、最新の情報や特定のドメインに関する深い知識が必要な場合に有効な手法です。
RAGの活用事例
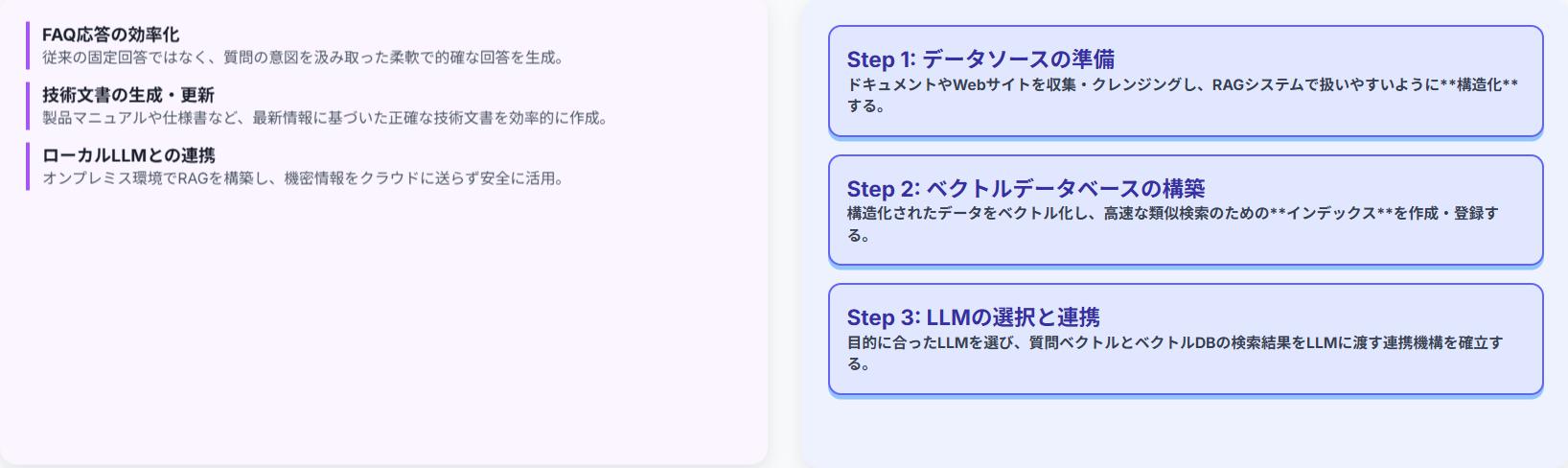
FAQ応答の効率化
RAGは、FAQ応答システムにおいて、質問に対する回答を迅速かつ正確に提供するために活用できます。TASUKIAnnotationのようなツールを利用して、FAQデータを構造化し、RAGシステムに組み込むことで、顧客からの問い合わせ対応を効率化できます。
RAG(検索拡張生成)は、FAQ応答システムにおいて、質問に対する回答を迅速かつ正確に提供するために活用できます。
従来のFAQシステムでは、事前に用意された回答の中から、質問に最も近いものを選択して提示するため、
質問の意図を正確に捉えられなかったり、適切な回答が見つからなかったりする場合があります。
RAGを導入することで、質問に基づいて関連する情報を外部のデータベースから検索し、その情報を基にLLMが回答を生成するため、より柔軟で的確なFAQ応答が可能になります。具体的には、ユーザーがFAQシステムに質問を入力すると、RAGは質問文を解析し、関連性の高いFAQ記事やドキュメントを検索します。
次に、検索された情報をLLMに入力として与え、質問に対する回答を生成させます。LLMは、質問文と関連情報の両方を考慮して回答を生成するため、質問の意図を正確に捉え、より適切な回答を提供することができます。
また、RAGは、FAQデータのメンテナンスを効率化するというメリットもあります。従来のFAQシステムでは、FAQ記事の追加や修正を手作業で行う必要がありましたが、RAGを導入することで、FAQデータを構造化し、RAGシステムに組み込むことで、FAQデータの更新を自動化することができます。これにより、FAQデータのメンテナンスにかかる時間とコストを削減することができます。
技術文書の生成
RAGは、技術文書の生成にも活用できます。例えば、製品のマニュアルや仕様書などの技術文書をRAGシステムに組み込むことで、LLMは常に最新の情報に基づいて文書を生成できます。これにより、文書作成の効率化や品質向上に貢献できます。
RAG(検索拡張生成)は、技術文書の生成にも非常に有効です。製品のマニュアルや仕様書などの技術文書は、専門的な知識や正確な情報が求められるため、作成に多くの時間と労力がかかります。
RAGを活用することで、LLMは常に最新の情報に基づいて文書を生成できるため、文書作成の効率化や品質向上に大きく貢献できます。
具体的には、まず、製品のマニュアルや仕様書などの技術文書をRAGシステムに組み込みます。
次に、LLMは、これらの文書を知識源として利用し、新しい技術文書を生成したり、既存の文書を更新したりすることができます。
例えば、新製品の発売に合わせて、LLMは既存の製品マニュアルを基に、新製品の情報を追加した新しいマニュアルを自動的に生成することができます。
また、製品の仕様変更があった場合、LLMは関連する文書を検索し、変更内容を反映した最新の仕様書を自動的に生成することができます。
RAGは、文書作成の効率化だけでなく、文書の品質向上にも貢献します。
LLMは、様々な情報源から情報を収集し、矛盾や誤りがないかを確認しながら文書を生成するため、人間が作成するよりも正確で信頼性の高い文書を作成することができます。これにより、技術文書の品質が向上し、顧客満足度の向上にもつながります。
ローカルLLMとRAG
ローカルLLMとRAGを組み合わせることで、より柔軟なシステム構築が可能です。例えば、OllamaのようなローカルLLMランタイムを利用し、RAGシステムを構築することで、クラウド環境に依存せずに、機密性の高い情報を安全に扱うことができます。
ローカルLLM(大規模言語モデル)とRAG(検索拡張生成)を組み合わせることで、より柔軟でセキュアなシステム構築が可能になります。従来のLLMは、クラウド環境で提供されることが一般的でしたが、ローカルLLMは、ユーザー自身の環境(オンプレミスサーバーや個人のPCなど)で動作させることができます。
これにより、クラウド環境への依存を減らし、データセキュリティを向上させることができます。
RAGは、LLMが持つ知識の限界を補完するために、外部の知識ソースから関連情報を検索し、LLMに提供する技術です。
ローカルLLMとRAGを組み合わせることで、機密性の高い情報をクラウドに送信することなく、LLMを活用することができます。
例えば、OllamaのようなローカルLLMランタイムを利用し、RAGシステムを構築することで、医療記録や金融情報などの機密性の高い情報を安全に扱うことができます。具体的には、ローカルLLMは、ユーザーの質問を受け付け、RAGは、質問に関連する情報をローカルのデータベースから検索します。
次に、RAGは、検索された情報をローカルLLMに提供し、LLMは、その情報に基づいて回答を生成します。
このプロセス全体がローカル環境で完結するため、機密性の高い情報が外部に漏洩するリスクを最小限に抑えることができます。
ローカルLLMとRAGの組み合わせは、データセキュリティを重視する企業や組織にとって、非常に魅力的な選択肢となります。
RAGの構築方法
データソースの準備
RAGを構築するためには、まず、適切なデータソースを準備する必要があります。データソースは、テキストデータやドキュメント、Webサイトなど、様々な形式で存在します。TASUKIAnnotation生成AI用データ構造化代行サービスを利用することで、データソースの構造化を効率的に行うことができます。
RAG(検索拡張生成)を構築するためには、まず、適切なデータソースを準備する必要があります。
データソースは、テキストデータやドキュメント、Webサイトなど、様々な形式で存在し、RAGシステムの性能に大きく影響します。
データソースの品質と網羅性が高ければ高いほど、RAGはより正確で信頼性の高い回答を生成することができます。
データソースの準備には、以下のステップが含まれます。
1.データソースの特定: RAGシステムが対象とするタスクやドメインに応じて、適切なデータソースを特定します。
例えば、FAQ応答システムの場合、FAQ記事や製品マニュアルなどがデータソースとなります。
2. データ収集:特定されたデータソースから、必要なデータを収集します。
データ収集には、WebスクレイピングやAPIの利用など、様々な方法があります。
3.データクレンジング: 収集されたデータには、ノイズや誤りが含まれている場合があります。
データクレンジングを行い、データの品質を向上させます。
4.データ構造化: RAGシステムが効率的にデータを検索できるように、データを構造化します。
例えば、テキストデータを段落や文ごとに分割したり、メタデータを付与したりします。
データソースの準備は、RAG構築において最も重要なステップの一つであり、
十分な時間と労力をかける必要があります。
TASUKIAnnotation生成AI用データ構造化代行サービスを利用することで、
データソースの構造化を効率的に行うことができます。
ベクトルデータベースの構築
ベクトルデータベースは、テキストデータをベクトルと呼ばれる数値データに変換し、効率的に検索するためのデータベースです。ベクトルデータベースを構築することで、RAGシステムは、質問に基づいて関連性の高い情報を迅速に検索できます。
ベクトルデータベースは、RAG(検索拡張生成)システムの中核となる要素の一つです。
テキストデータをベクトルと呼ばれる数値データに変換し、そのベクトルを用いて効率的に類似検索を行うためのデータベースです。
従来のデータベースでは、テキストデータを文字列として扱い、キーワードやフレーズに基づいて検索を行っていましたが、ベクトルデータベースでは、テキストデータの意味的な類似性を考慮して検索を行うことができます。
ベクトルデータベースを構築することで、RAGシステムは、質問に基づいて関連性の高い情報を迅速に検索できるようになります。具体的には、以下の手順でベクトルデータベースを構築します。
1.テキストデータのベクトル化: テキストデータをベクトルと呼ばれる数値データに変換します。
この処理には、Word2VecやBERTなどの自然言語処理モデルが用いられます。
2. ベクトルのインデックス作成:ベクトルを効率的に検索できるように、インデックスを作成します。
インデックスには、KD木やHNSWなどのアルゴリズムが用いられます。
3.データベースへの登録:ベクトルとそれに対応するテキストデータをデータベースに登録します。
ベクトルデータベースは、RAGシステムの性能に大きく影響するため、
適切なベクトル化モデルやインデックスアルゴリズムを選択する必要があります。
LLMの選択と連携
RAGシステムを構築するためには、適切なLLMを選択し、ベクトルデータベースと連携する必要があります。LLMは、質問応答タスクに特化したモデルや、汎用的な言語モデルなど、様々な種類があります。目的に応じて適切なLLMを選択し、RAGシステムに組み込むことで、より高度な質問応答が可能になります。
RAG(検索拡張生成)システムを構築する上で、適切なLLM(大規模言語モデル)の選択と、ベクトルデータベースとの連携は非常に重要な要素です。
LLMは、質問応答タスクに特化したモデルや、汎用的な言語モデルなど、様々な種類が存在し、それぞれに得意とする領域や特性が異なります。
そのため、RAGシステムを構築する際には、目的とするタスクや要件に応じて、最適なLLMを選択する必要があります。例えば、専門的な知識を必要とする質問応答タスクであれば、特定のドメインに特化したLLMを選択することが望ましいでしょう。
一方、幅広い知識を必要とする質問応答タスクであれば、汎用的な言語モデルを選択することが適切かもしれません。
LLMを選択したら、次にベクトルデータベースとの連携を行います。ベクトルデータベースは、テキストデータをベクトルと呼ばれる数値データに変換し、
効率的に検索するためのデータベースです。
RAGシステムでは、LLMはベクトルデータベースから検索された関連情報を基に、質問に対する回答を生成します。そのため、LLMとベクトルデータベースが適切に連携することで、より高度な質問応答が可能になります。
具体的には、LLMはベクトルデータベースに対して質問ベクトルを送信し、ベクトルデータベースは質問ベクトルに類似するベクトルを持つテキストデータを検索します。次に、LLMは検索されたテキストデータを基に、質問に対する回答を生成します。
このプロセスを通じて、RAGシステムは、LLMが持つ知識の限界を補完し、より正確で信頼性の高い回答を生成することができます。
まとめ
RAGの今後の展望
RAGは、LLMの精度と信頼性を向上させるための重要な技術であり、今後ますますその重要性が高まっていくと考えられます。RAGの技術は、様々な分野での応用が期待されており、今後の発展が注目されます。
RAG(検索拡張生成)は、大規模言語モデル(LLM)の精度と信頼性を向上させるための重要な技術であり、今後ますますその重要性が高まっていくと考えられます。LLMは、その強力な自然言語処理能力により、様々な分野で活用されていますが、学習データに含まれていない情報や最新の情報に対応できないという課題があります。
RAGは、この課題を解決するために、外部の知識ソースから関連情報を検索し、LLMに提供することで、常に最新の情報に基づいて回答を生成できるようにします。
RAGの技術は、様々な分野での応用が期待されており、今後の発展が注目されます。例えば、医療分野では、RAGを用いて、患者の症状や検査結果に基づいて、最新の医学知識に基づいた診断や治療法の提案を行うことができます。また、金融分野では、RAGを用いて、市場の動向や企業の財務状況に基づいて、
より正確な投資判断を支援することができます。
さらに、教育分野では、RAGを用いて、学生の学習状況や理解度に合わせて、最適な学習教材や学習方法を提供することができます。
RAGは、LLMの可能性を最大限に引き出すための鍵となる技術であり、今後ますますその重要性が高まっていくと考えられます。
RAGの研究開発は、今後も活発に進められ、より高度なRAG技術が登場することが期待されます。










