

自然言語処理(NLP)は、AI技術の中でも特に注目されている分野です。この記事では、自然言語処理の基本的な概念から、仕組み、活用事例まで、初心者にもわかりやすく解説します。AIチャットボット、音声認識、翻訳機能など、身近な例を交えながら、自然言語処理の世界を探求しましょう。
自然言語処理(NLP)とは何か?
とは何か?.png)
自然言語の定義と特徴
自然言語とは、私たちが日常的に使用している言語のことです。文法や意味構造を持ち、コミュニケーションを円滑に行うためのツールとして機能します。自然言語処理では、これらの言語をコンピュータが理解し、処理できるようにするための技術を開発します。
人工言語との違い
人工言語は、特定の目的のために人為的に作られた言語であり、自然言語のような曖昧さや多様性がありません。プログラミング言語などが代表例です。自然言語処理では、この曖昧さや多様性に対応する必要があるため、高度な技術が求められます。
自然言語処理が注目される背景
近年、テキストデータの爆発的な増加や、AI技術の発展に伴い、自然言語処理の重要性が高まっています。企業は、これらのデータを活用して、顧客対応の自動化や、市場分析、製品開発など、さまざまな分野で自然言語処理を活用しようとしています。またBERTやGPT-3など、汎用言語モデルの進化も著しいです。
自然言語処理でできること
テキストデータの解析
大量のテキストデータから、有用な情報を抽出することができます。例えば、顧客のレビューから製品の改善点を見つけたり、SNSの投稿からトレンドを把握したりすることができます。
AIチャットボット
自然言語処理を活用したAIチャットボットは、顧客からの問い合わせに自動で対応することができます。これにより、顧客対応の効率化や、24時間365日のサポート体制の構築が可能になります。
音声認識AI
音声認識AIは、人間の音声をテキストに変換することができます。これにより、会議の議事録作成や、音声による操作などが可能になります。
自然言語処理の仕組みを理解する
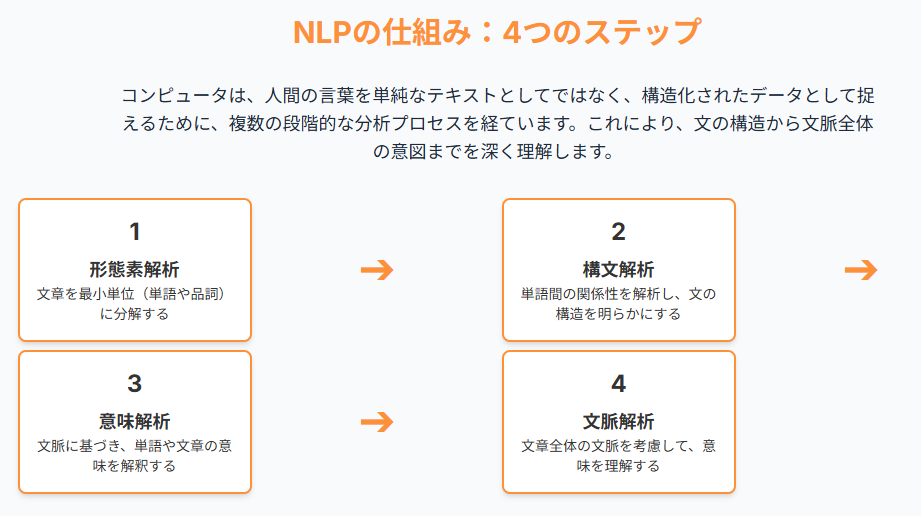
形態素解析
文章を単語や品詞などの最小単位に分解する処理です。これにより、文章の構造を解析し、意味を理解するための基礎を築きます。
構文解析
単語間の関係性を解析し、文の構造を明らかにします。これにより、文の意味をより正確に理解することができます。
意味解析
文の意味を解釈し、文脈における単語やフレーズの意味を特定します。これにより、文全体の意味を理解することができます。
文脈解析
文章全体の文脈を考慮して、文の意味を解釈します。これにより、文章の意図や背景を理解することができます。
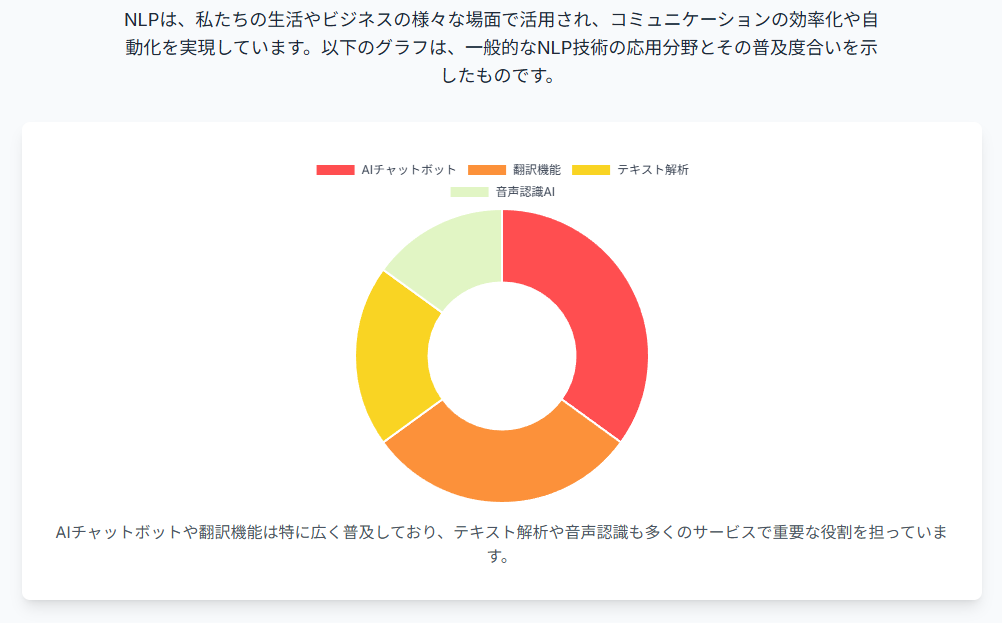
自然言語処理の活用事例
キャッシュビーデータ|CASHb
キャッシュバック提供アプリ『CASHb』の画像処理技術改善に貢献しています。
AIスピーカー
AIスピーカーは、自然言語処理を活用して、人間の言葉を理解し、応答することができます。これにより、音楽の再生や、ニュースの読み上げ、家電の操作などが可能になります。
翻訳機能
自然言語処理を活用した翻訳機能は、異なる言語間の翻訳を自動で行うことができます。これにより、言語の壁を越えたコミュニケーションが可能になります。
今後の自然言語処理
さらなる発展と課題
自然言語処理は、今後ますます発展していくことが期待されます。しかし、自然言語の曖昧さや、文化的な背景など、解決すべき課題も多く存在します。これらの課題を克服し、より高度な自然言語処理技術を開発することで、私たちの生活はより豊かになるでしょう。
自然言語処理の歴史
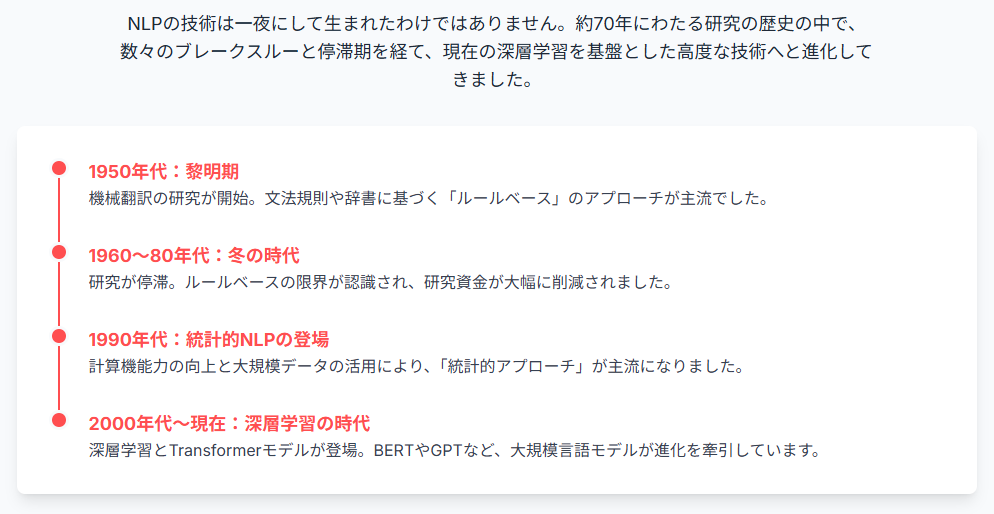
黎明期:1950年代
自然言語処理の歴史は、1950年代の初期の機械翻訳の研究に遡ります。第二次世界大戦後、冷戦時代に突入し、敵国の情報を迅速に収集・分析する目的で、アメリカを中心に機械翻訳の研究が盛んに行われました。この頃は、ルールベースのアプローチが主流であり、文法規則や辞書を用いて翻訳が行われていました。しかし、初期の機械翻訳システムは、精度が低く、実用的なレベルには達しませんでした。たとえば、ある有名な例として、「Thespirit is willing but the flesh is weak.」という英文をロシア語に翻訳し、それを再び英語に翻訳した結果、「Thevodka is good but the meat isrotten.(ウォッカは良いが、肉は腐っている)」という全く異なる意味になったという逸話があります。このエピソードは、当時の機械翻訳の限界を示すものとして広く知られています。
冬の時代:1960年代後半~1980年代
1960年代後半になると、機械翻訳の研究に対する批判が高まりました。特に、ALPAC(AutomaticLanguage Processing AdvisoryCommittee)による報告書が、機械翻訳の現状に対する厳しい評価を下し、研究資金が大幅に削減されました。これにより、自然言語処理の研究は一時的に停滞し、「冬の時代」と呼ばれる時期に入りました。この時期には、ルールベースのアプローチの限界が認識され、より高度な言語処理技術の必要性が認識されました。しかし、当時の計算機能力やデータ量の制約から、ブレークスルーはなかなか起こりませんでした。
統計的自然言語処理の登場:1990年代
1990年代に入ると、計算機能力の向上と大規模なテキストデータの利用が可能になったことで、統計的な手法を用いた自然言語処理が注目を集めるようになりました。特に、コーパスと呼ばれる大量のテキストデータから、単語や文の出現頻度などの統計情報を学習し、それに基づいて言語処理を行う手法が主流となりました。このアプローチにより、機械翻訳や音声認識の精度が大幅に向上し、実用的なシステムが開発されるようになりました。IBMが開発した機械翻訳システム「Candide」や、Googleの初期の検索エンジンなどが、この時期の代表的な成果です。
機械学習と深層学習の導入:2000年代~現在
2000年代以降、機械学習の技術が自然言語処理に導入され、さらに2010年代には深層学習(ディープラーニング)の技術が急速に発展しました。深層学習は、多層のニューラルネットワークを用いて、大量のデータから自動的に特徴量を学習する手法であり、画像認識や音声認識などの分野で大きな成功を収めています。自然言語処理においても、深層学習の導入により、翻訳、テキスト分類、質問応答など、様々なタスクの精度が飛躍的に向上しました。特に、2018年にGoogleが発表したBERT(BidirectionalEncoder Representations fromTransformers)は、自然言語処理の分野に革命をもたらし、その後のGPTシリーズなどの汎用言語モデルの開発につながりました。
近年の自然言語処理の進展
Transformerモデルの登場
2017年に発表されたTransformerモデルは、自然言語処理の分野に大きな変革をもたらしました。それまでの主流であったRNN(RecurrentNeuralNetwork)に比べて、並列処理が可能であり、より大規模なデータの学習に適しています。また、Attention機構により、文中の単語間の依存関係を効率的に捉えることができます。TransformerモデルをベースにしたBERTやGPTなどのモデルは、様々な自然言語処理タスクで高い性能を発揮し、その応用範囲は広がっています。
事前学習とファインチューニング
近年、大規模なテキストデータを用いて事前学習された言語モデルを、特定のタスクに合わせてファインチューニングする手法が一般的になっています。これにより、少ないデータでも高い精度を達成することが可能になり、自然言語処理の応用範囲が広がりました。例えば、BERTは、Wikipediaや書籍などの大量のテキストデータを用いて事前学習され、その後、質問応答やテキスト分類などのタスクに合わせてファインチューニングされます。
Few-shotLearningとZero-shotLearning
Few-shotLearningは、少量のデータから学習する手法であり、Zero-shotLearningは、全くデータなしで学習する手法です。これらの手法は、データが少ない場合や、新しいタスクに適用する場合に有効です。GPT-3などの大規模言語モデルは、Few-shotLearningやZero-shotLearningの能力を備えており、様々なタスクに柔軟に対応することができます。例えば、GPT-3は、いくつかの例を与えるだけで、新しい言語の翻訳や、複雑な文章の生成を行うことができます。
自然言語処理の倫理的な課題
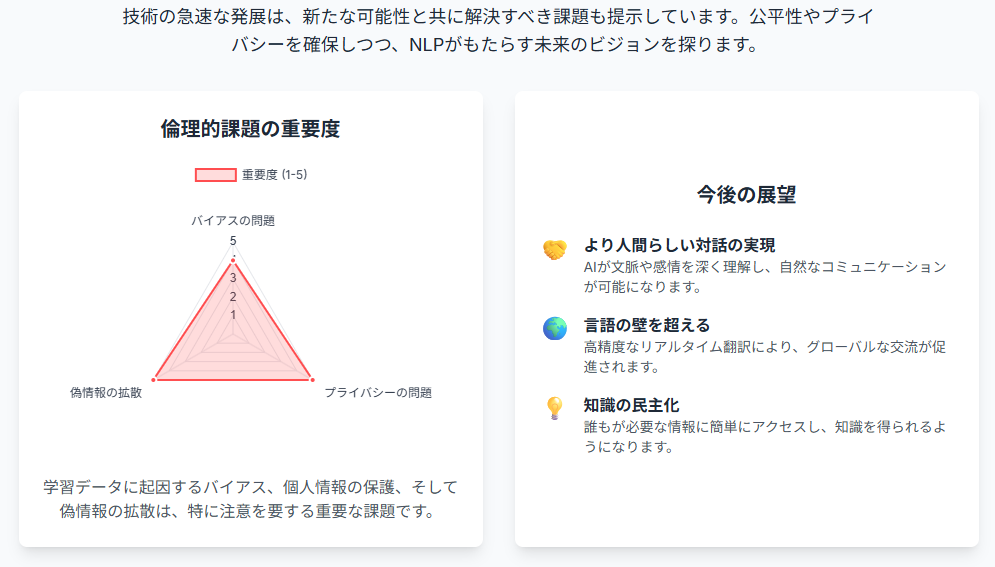
バイアスの問題
自然言語処理モデルは、学習データに含まれるバイアスを学習してしまう可能性があります。例えば、特定の性別や人種に対する偏見が含まれたデータで学習されたモデルは、その偏見を反映した結果を出力する可能性があります。このようなバイアスの問題は、公平性や倫理的な観点から重要な課題であり、解決に向けて様々な研究が行われています。バイアスの軽減には、学習データの多様性を確保する、バイアスを検出して修正する、などのアプローチがあります。
プライバシーの問題
自然言語処理モデルは、個人情報を含むテキストデータを扱うことがあります。これらのデータを適切に保護し、プライバシーを侵害しないようにする必要があります。例えば、医療記録や金融取引の記録などの機密性の高いデータを扱う場合には、データの匿名化や暗号化などの対策を講じる必要があります。また、モデルの学習に用いるデータの利用規約を明確にし、ユーザーの同意を得ることも重要です。
偽情報の拡散
自然言語処理技術は、偽情報を生成したり、拡散したりするために悪用される可能性があります。例えば、自動生成されたフェイクニュースや、特定の意見を強調するプロパガンダなどが、社会に混乱をもたらす可能性があります。このような偽情報の拡散を防ぐためには、偽情報を検出する技術の開発や、メディアリテラシーの向上などが重要です。また、プラットフォーム事業者によるコンテンツの監視や、ファクトチェック機関との連携も有効です。
自然言語処理の応用分野
カスタマーサポート
AIチャットボットによる自動応答、FAQの自動生成、顧客の問い合わせ内容の分析など、カスタマーサポート業務の効率化に貢献します。例えば、顧客からの問い合わせ内容を自然言語処理で解析し、適切な回答を自動で生成したり、FAQを自動的に作成したりすることができます。また、顧客の感情を分析し、優先的に対応すべき顧客を特定することも可能です。これにより、顧客満足度の向上や、コスト削減につながります。
医療・ヘルスケア
電子カルテの解析、医療論文の検索、患者の症状に基づいた診断支援など、医療現場での活用が進んでいます。自然言語処理を活用することで、医師の負担を軽減し、より正確な診断を支援することができます。例えば、電子カルテの自由記述欄に記載された情報を解析し、患者の病歴や症状を抽出したり、医療論文のデータベースから必要な情報を迅速に検索したりすることができます。また、患者の症状に関する情報を入力することで、可能性のある疾患を提示する診断支援システムも開発されています。
金融
不正検知、リスク管理、顧客のsentiment分析など、金融機関における業務の効率化や高度化に貢献します。例えば、不正な取引を検出するために、取引履歴や顧客の情報を自然言語処理で解析したり、リスクを評価するために、ニュース記事やSNSの情報を分析したりすることができます。また、顧客のsentimentを分析し、顧客満足度を向上させるための施策を検討することも可能です。
法律
契約書のレビュー、判例検索、法律相談チャットボットなど、法律業務の効率化に貢献します。自然言語処理を活用することで、弁護士の負担を軽減し、より迅速かつ正確な法的サービスを提供することができます。例えば、契約書の内容を自動的にレビューし、リスクのある条項を検出したり、判例データベースから必要な情報を迅速に検索したりすることができます。また、法律に関する質問に自動で回答するチャットボットを開発し、一般の人々が気軽に法律相談を利用できるようにすることも可能です。
教育
文章の添削、自動採点、学習コンテンツのパーソナライズなど、教育分野での活用が期待されています。自然言語処理を活用することで、教師の負担を軽減し、生徒一人ひとりに合わせた教育を提供することができます。例えば、生徒が書いた文章を自動的に添削し、文法や表現の誤りを指摘したり、テストの答案を自動的に採点したりすることができます。また、生徒の学習履歴や興味関心に基づいて、最適な学習コンテンツを推薦することも可能です。
自然言語処理を学ぶためのリソース
書籍
自然言語処理に関する書籍は、基礎から応用まで幅広く出版されています。初心者向けの入門書から、専門家向けの高度な解説書まで、自分のレベルに合った書籍を選ぶことができます。例えば、「入門自然言語処理」や「自然言語処理の基礎」などの書籍は、自然言語処理の基本的な概念や手法をわかりやすく解説しています。また、「深層学習による自然言語処理」や「Transformerによる自然言語処理」などの書籍は、最新の深層学習技術を用いた自然言語処理について詳しく解説しています。
オンラインコース
CourseraやUdemyなどのオンライン学習プラットフォームでは、自然言語処理に関する様々なコースが提供されています。これらのコースでは、ビデオ講義や演習問題を通じて、自然言語処理の知識やスキルを習得することができます。例えば、スタンフォード大学の「NaturalLanguage Processing with Deep Learning」や、deeplearning.aiの「Natural LanguageProcessingSpecialization」などのコースは、自然言語処理の分野で非常に人気があります。
論文
自然言語処理の最新の研究成果は、主に論文として発表されます。arXivなどのプレプリントサーバーや、ACL、EMNLP、NAACLなどの国際会議のproceedingsをチェックすることで、最新の研究動向を把握することができます。ただし、論文を読むには、ある程度の専門知識が必要となるため、初心者には難しいかもしれません。まずは、解説記事やブログなどを読んで、基本的な知識を身につけることをお勧めします。
コミュニティ
自然言語処理の研究者やエンジニアが集まるコミュニティに参加することで、情報交換や交流を行うことができます。例えば、GitHubやStackOverflowなどのプラットフォームでは、自然言語処理に関する様々な質問や議論が行われています。また、Meetupなどのイベントに参加することで、直接顔を合わせて交流することも可能です。コミュニティに参加することで、モチベーションを維持したり、新しい知識やスキルを習得したりすることができます。
自然言語処理の将来展望
より人間らしい対話の実現
自然言語処理の進展により、AIがより自然で人間らしい対話を行うことができるようになるでしょう。これにより、AIチャットボットやバーチャルアシスタントが、より高度なタスクを実行したり、より自然なコミュニケーションを実現したりすることが可能になります。例えば、AIが顧客の感情を理解し、適切な対応をしたり、AIが個人の興味関心に基づいて、最適な情報を提供したりすることが考えられます。
言語の壁を超える
自然言語処理の進展により、異なる言語間の翻訳がより正確かつ自然になるでしょう。これにより、言語の壁を越えたコミュニケーションが容易になり、グローバルなビジネスや交流が促進されることが期待されます。例えば、AIがリアルタイムで翻訳を行い、異なる言語を話す人々がスムーズにコミュニケーションをとったり、AIが自動的に多言語のコンテンツを生成したりすることが考えられます。
知識の民主化
自然言語処理の進展により、大量の情報を効率的に処理し、必要な知識を抽出することが容易になるでしょう。これにより、誰もが簡単に知識にアクセスできるようになり、知識の民主化が進むことが期待されます。例えば、AIが自動的に情報を要約し、必要な情報を抽出したり、AIが個人の質問に答えることで、知識の習得を支援したりすることが考えられます。










