

世界的なAI開発競争が激化する中、日本独自の進化を遂げる国産LLM(大規模言語モデル)。その現状、海外LLMとの差別化、開発事例、そして今後の展望について徹底解説します。
国産LLMの現状と課題
国産LLM開発の現状
世界的なAI開発競争が激化する中、日本国内でも独自のLLM開発が活発に進められています。これは、単なる技術的な挑戦に留まらず、言語や文化への深い理解に基づく、より人間らしいAIの実現を目指す動きと言えるでしょう。NTTの「tsuzumi」は、その代表例の一つであり、日本語の特性を最大限に活かした自然な対話能力が期待されています。
サイバーエージェントの「CyberAgentLM」も、広告やエンターテインメント分野での活用を見据え、独自のデータセットと学習方法を用いて開発が進められています。これらの事例に加えて、様々な企業や研究機関が、日本語に特化したLLMの開発に力を入れています。その背景には、グローバルなプラットフォームに依存しない、自国の言語と文化に根ざしたAI技術を確立したいという強い意志があります。
さらに、これらのLLM開発は、単に既存の技術を模倣するのではなく、新しいアルゴリズムや学習手法の研究開発にも繋がっており、日本のAI技術全体の底上げに貢献することが期待されています。
国産LLMの課題
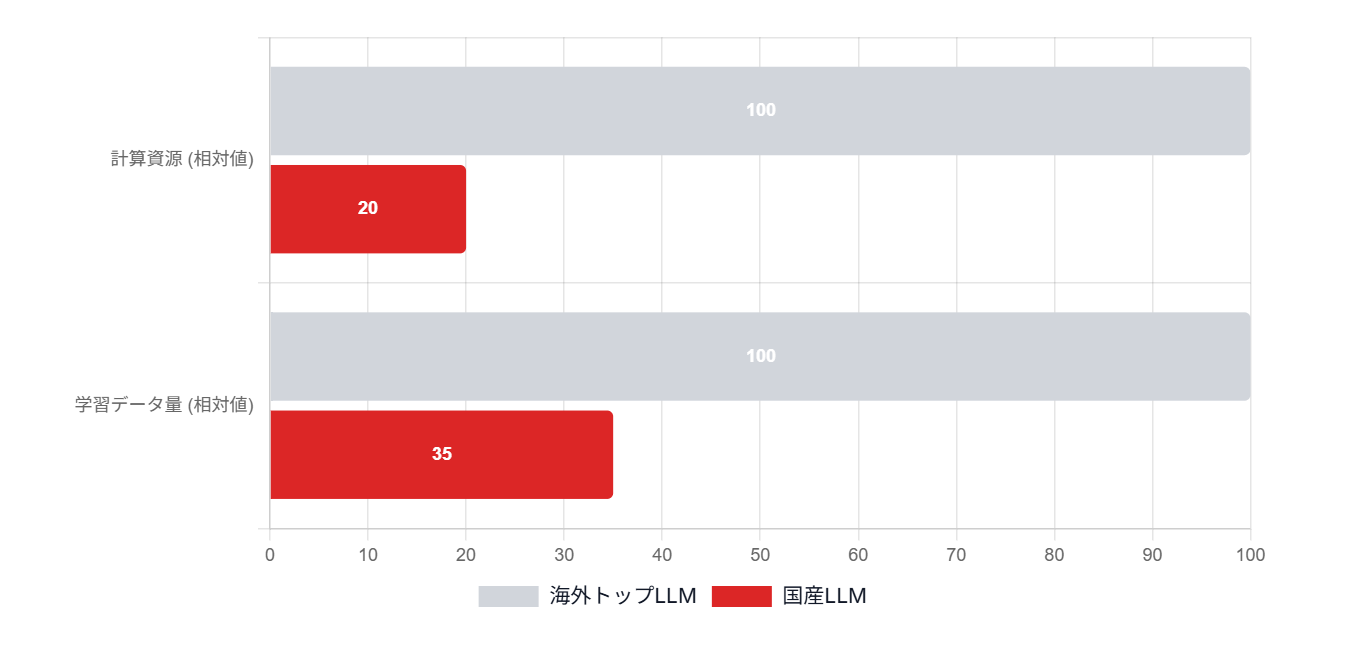
国産LLMの開発は目覚ましい進歩を遂げているものの、依然として克服すべき課題が山積しています。特に、計算資源の制約は深刻であり、大規模なデータセットを用いた学習には、多大なコストと時間が必要となります。海外の大規模LLMと比較して、性能面で劣る部分が存在することも否定できません。
データ量の不足もまた、国産LLMの成長を阻む大きな要因の一つです。日本語のデータセットは、英語などの主要言語と比較して量が限られており、多様な表現や専門的な知識を学習させるためには、更なるデータ収集と整備が不可欠です。また、データの質も重要であり、ノイズの多いデータや偏ったデータは、LLMの性能を低下させる可能性があります。
さらに、人材不足も深刻な問題です。LLMの開発には、高度な専門知識と経験を持つAIエンジニアや研究者が必要ですが、国内ではその数が限られています。人材育成の強化と、海外からの優秀な人材の誘致が急務となっています。これらの課題を克服し、国産LLMが国際的な競争力を獲得するためには、産官学連携による総合的な取り組みが不可欠です。
ガラパゴス化の懸念
国産LLMが独自の進化を遂げることは、日本のAI技術の多様性を高める上で重要な意味を持ちます。しかし、その一方で、国際的な標準から乖離し、ガラパゴス化する可能性も指摘されています。ガラパゴス化とは、特定の地域や市場において独自の進化を遂げた技術や製品が、国際的な競争力を失ってしまう現象を指します。
LLMの場合、独自のデータセットや学習方法を用いることで、日本語の処理能力は向上するかもしれませんが、他の言語やタスクへの適応性が低下する可能性があります。また、国際的な研究コミュニティとの連携が不足すると、最新の研究成果を取り入れることが遅れ、技術的な遅れが生じることも考えられます。
今後の開発においては、国際的な連携や標準化への対応も重要となります。具体的には、国際的なベンチマークテストへの参加や、オープンソースプロジェクトへの貢献などが挙げられます。また、多言語対応や、様々なタスクへの適応性を高めるための研究開発も必要となります。ガラパゴス化を回避し、国際的な競争力を維持するためには、グローバルな視点を持つことが不可欠です。
国産LLMの強みと海外LLMとの差別化
日本語処理能力の高さ
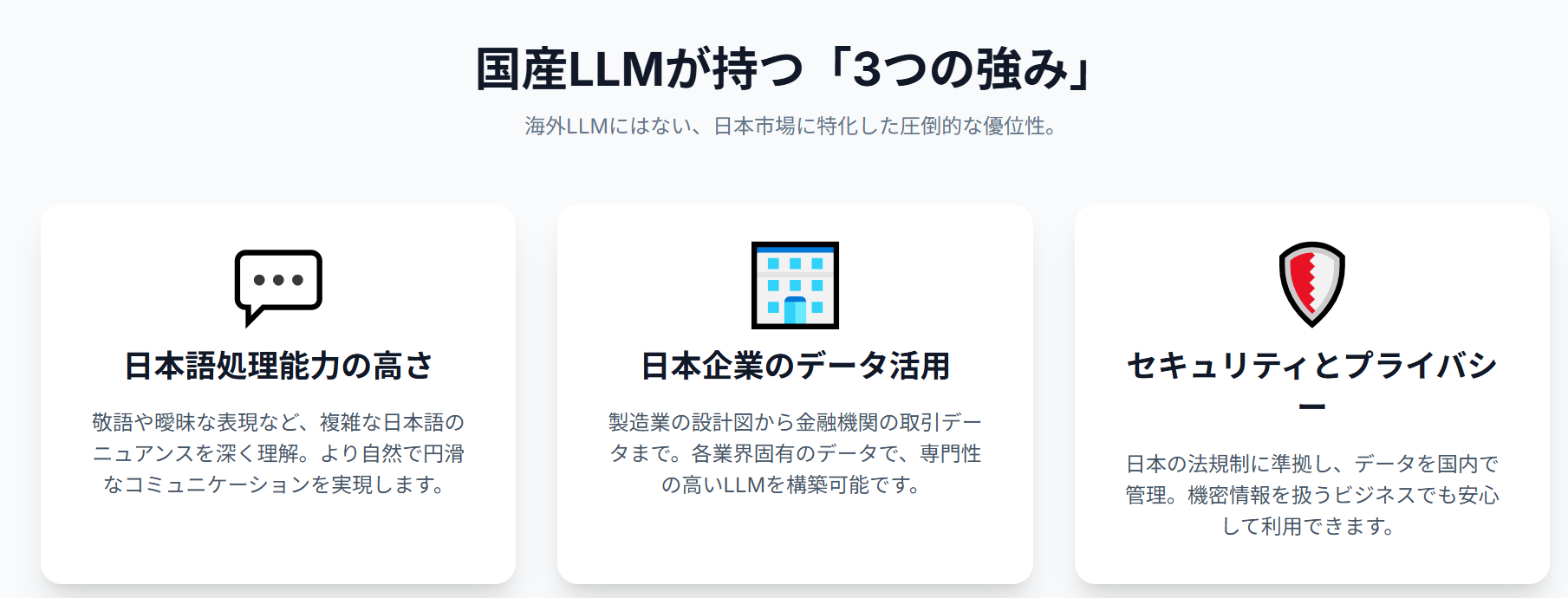
国産LLMの最大の強みは、何と言っても日本語の処理能力の高さです。海外LLMと比較して、日本語の微妙なニュアンスや文化的な背景を理解する能力に優れています。これは、長年にわたる日本語研究の蓄積と、日本語に特化したデータセットの活用によって実現されています。
具体的には、敬語や謙譲語の使い分け、比喩表現や慣用句の理解、そして文脈に応じた適切な応答などが挙げられます。これらの能力は、ビジネスシーンや日常生活において、より自然で円滑なコミュニケーションを可能にします。また、日本語のテキストデータからの情報抽出や分析においても、国産LLMは高い精度を発揮します。
例えば、顧客からの問い合わせ対応や、市場調査におけるアンケート分析など、様々な業務において、国産LLMを活用することで、効率化と品質向上が期待できます。海外LLMでは十分に理解できない日本語特有の表現やニュアンスを的確に捉え、より精度の高い分析結果を提供することができます。
日本企業のデータ活用
日本企業が持つ独自のデータを活用することで、特定の業界や業務に特化したLLMを開発することができます。これは、海外LLMでは対応できない高度なニーズに応えることが可能になる、大きな差別化要因となります。例えば、製造業であれば、製品設計データや製造プロセスデータを活用して、品質管理や生産性向上に役立つLLMを開発することができます。
金融機関であれば、顧客の取引データや市場データを活用して、リスク管理や不正検知に役立つLLMを開発することができます。医療機関であれば、患者の診療データや研究データを活用して、診断支援や新薬開発に役立つLLMを開発することができます。これらの事例は、ほんの一例に過ぎません。日本企業が持つ独自のデータを活用することで、LLMの可能性は無限に広がります。
ただし、データの利活用には、個人情報保護やセキュリティ対策など、様々な課題も存在します。これらの課題を克服し、安全かつ有効にデータを活用するためには、適切なガバナンス体制の構築と、高度な技術が必要です。
セキュリティとプライバシー
データセキュリティやプライバシー保護に対する意識の高まりから、国内で開発されたLLMへのニーズが高まっています。国産LLMは、日本の法規制や企業文化に合わせた安全な利用を可能にします。海外LLMの場合、データの保管場所や利用規約が海外の法律に準拠しているため、日本の企業が利用する際には、法的なリスクやセキュリティ上の懸念が生じる可能性があります。
国産LLMであれば、データの保管場所を国内に限定したり、日本の法律に準拠した利用規約を設定したりすることができます。また、日本の企業文化や商習慣に合わせたカスタマイズも容易です。これにより、企業は安心してLLMを利用することができます。さらに、国産LLMは、セキュリティ対策にも力を入れています。データの暗号化やアクセス制御、不正アクセスの監視など、様々な対策を講じることで、データの漏洩や改ざんを防止します。
これらのセキュリティ対策は、企業の信頼性を高める上でも重要な要素となります。近年、データ漏洩事件が多発しており、企業のセキュリティ対策に対する社会的な関心が高まっています。国産LLMは、高いセキュリティレベルを維持することで、企業の信頼性を向上させ、安心して利用できる環境を提供します。
国産LLMの開発事例

NECのLLM活用事例
NECは、自社開発のLLMを活用して、顧客対応業務の効率化や新製品開発の支援など、幅広い分野で成果を上げています。特に、金融機関向けのAIチャットボットの開発においては、高い評価を得ています。このAIチャットボットは、顧客からの問い合わせに自然な日本語で対応し、待ち時間の短縮や顧客満足度の向上に貢献しています。
また、NECは、LLMを活用して、新製品開発のアイデア出しや、市場調査の分析も行っています。LLMは、大量のテキストデータを分析し、潜在的なニーズやトレンドを発見することができます。これにより、NECは、より市場ニーズに合致した製品を開発し、競争力を強化することができます。さらに、NECは、LLMを活用して、社内のナレッジマネジメントも行っています。LLMは、社内のドキュメントや情報を分析し、必要な情報を迅速に提供することができます。
これにより、社員は、より効率的に業務を遂行し、生産性を向上させることができます。NECのLLM活用事例は、LLMが様々な分野で活用できる可能性を示しており、他の企業にとっても参考になるでしょう。
SB Intuitions株式会社の事例
SBIntuitions株式会社は、LLMを活用して、企業のマーケティング活動を支援するサービスを提供しています。顧客のニーズに合わせた最適なコンテンツ生成や、広告効果の最大化を実現しています。具体的には、LLMを活用して、広告文の作成、キャッチコピーの生成、そしてターゲット顧客に合わせたメールマガジンの作成などを行っています。
LLMは、顧客の属性情報や過去の購買履歴などを分析し、最適なコンテンツを生成することができます。これにより、広告のクリック率やコンバージョン率を向上させることができます。また、SBIntuitions株式会社は、LLMを活用して、顧客のブランドイメージを向上させるための施策も行っています。LLMは、ブランドイメージに合致したコンテンツを生成し、SNSやブログなどで発信することで、顧客のブランド認知度を高めることができます。
さらに、SBIntuitions株式会社は、LLMを活用して、競合他社の分析も行っています。LLMは、競合他社のウェブサイトやSNSなどを分析し、強みや弱みを把握することができます。これにより、顧客は、より効果的なマーケティング戦略を立案し、競争優位性を確立することができます。SBIntuitions株式会社の事例は、LLMがマーケティング分野において、大きな可能性を秘めていることを示しています。
東京大学松尾研究室「Weblab-10B」
東京大学松尾研究室が開発した「Weblab-10B」は、研究目的で公開されているLLMであり、学術的な研究だけでなく、企業におけるLLMの PoC(概念実証)などにも活用されています。このLLMは、日本語のテキストデータを用いて学習されており、日本語の処理能力に優れています。また、比較的軽量であるため、中小企業やスタートアップ企業でも扱いやすいという特徴があります。
Weblab-10Bは、様々なタスクに利用することができます。例えば、文章の要約、質問応答、そしてテキスト生成などが挙げられます。企業は、Weblab-10Bを活用して、自社の業務プロセスを効率化したり、新しいサービスを開発したりすることができます。また、Weblab-10Bは、オープンソースとして公開されているため、誰でも自由に利用することができます。
これにより、LLMの研究開発が加速し、様々な応用事例が生まれることが期待されます。東京大学松尾研究室は、Weblab-10Bの他にも、様々なAI技術の研究開発を行っており、日本のAI技術の発展に大きく貢献しています。Weblab-10Bは、日本のAI技術の可能性を示す好例と言えるでしょう。
国産LLMの今後の展望
さらなる性能向上
国産LLMの性能向上は、今後の重要な課題です。計算資源の確保やデータ量の拡充、そして革新的なアルゴリズムの開発を通じて、海外LLMに匹敵する性能を目指す必要があります。具体的には、より大規模なGPUクラスタの構築や、クラウドサービスの活用などが考えられます。また、データ量の拡充に向けては、ウェブデータの収集だけでなく、書籍や論文などの専門的なデータセットの整備も重要となります。
さらに、アルゴリズムの開発においては、Transformer以外の新しいアーキテクチャの研究や、効率的な学習方法の開発などが求められます。性能向上は、LLMの応用範囲を広げる上で不可欠な要素です。性能が向上すれば、より複雑なタスクを処理できるようになり、より高度なサービスを提供できるようになります。例えば、医療分野においては、診断支援や新薬開発に役立つLLMを開発することができます。
金融分野においては、リスク管理や不正検知に役立つLLMを開発することができます。これらの応用事例は、ほんの一例に過ぎません。性能向上によって、LLMの可能性は無限に広がります。
多様な分野での応用
今後は、医療、教育、金融など、様々な分野でのLLMの応用が期待されます。各分野の専門知識とLLMを組み合わせることで、新たな価値を創造することができます。医療分野においては、LLMを活用して、医師の診断を支援したり、患者のケアプランを作成したりすることができます。また、新薬開発の過程においても、LLMを活用することで、効率化と精度向上が期待できます。
教育分野においては、LLMを活用して、生徒一人ひとりに合わせた学習プランを作成したり、質問に答えたりすることができます。また、教師の負担を軽減するための教材作成や採点業務の支援も可能です。金融分野においては、LLMを活用して、リスク管理や不正検知を行ったり、顧客の投資アドバイスを行ったりすることができます。
また、顧客対応業務の効率化や、新しい金融商品の開発にも役立ちます。これらの分野以外にも、製造業、建設業、そしてエンターテインメント業など、様々な分野でLLMの応用が期待されます。各分野の専門家とLLM開発者が協力し、それぞれのニーズに合わせたLLMを開発することで、社会全体の発展に貢献することができます。
オープンソース化の推進
国産LLMのオープンソース化を推進することで、技術開発の加速や人材育成に貢献することができます。また、中小企業やスタートアップ企業がLLMを活用する機会を増やすことができます。オープンソース化とは、ソフトウェアのソースコードを公開し、誰でも自由に利用、修正、そして再配布できるようにすることです。LLMをオープンソース化することで、様々な研究者やエンジニアがLLMの改善に貢献することができます。
これにより、技術開発が加速し、より高性能なLLMが生まれることが期待されます。また、オープンソース化は、人材育成にも貢献します。LLMのソースコードを公開することで、学生やエンジニアは、LLMの内部構造を理解し、技術を習得することができます。さらに、中小企業やスタートアップ企業は、オープンソースのLLMを活用することで、自社でLLMを開発するコストを削減することができます。
これにより、LLMの利用が促進され、様々な分野での応用が期待されます。ただし、オープンソース化には、セキュリティ上のリスクや、知的財産権の問題なども存在します。これらの課題を克服し、安全かつ有効にオープンソース化を推進するためには、適切なルールとガバナンス体制の構築が不可欠です。
まとめ:国産LLMの未来
国産LLMは、日本語処理能力の高さやデータセキュリティの面で強みを持ち、日本独自のニーズに応える可能性を秘めています。今後の開発においては、国際的な連携やオープンソース化を推進し、多様な分野での応用を目指すことで、AI技術の発展に大きく貢献することが期待されます。国産LLMの開発は、単なる技術的な挑戦に留まらず、日本の経済成長や社会課題の解決にも貢献する可能性を秘めています。
そのため、政府、企業、そして研究機関が連携し、国産LLMの開発を積極的に支援していく必要があります。また、国産LLMの利用を促進するためには、人材育成や、LLMに関する知識の普及も重要となります。これらの取り組みを通じて、国産LLMは、日本の未来を明るく照らす存在となるでしょう。
世界に貢献できるようなLLMを開発し、AI技術の発展に大きく貢献することが期待されます。技術開発、人材育成、そして知識の普及を継続することで、国産LLMは、より多くの分野で活用され、社会全体の発展に大きく貢献するでしょう。










