
AIモデルの学習効率を飛躍的に向上させる転移学習とファインチューニング。本記事では、これらの技術の違いを明確にし、それぞれのメリット・デメリット、活用事例を詳しく解説します。さらに、OpenAIのChatGPTなどの大規模言語モデル(LLM)を効率的に活用するための学習方法についてもご紹介します。
転移学習とファインチューニング:基本概念の整理
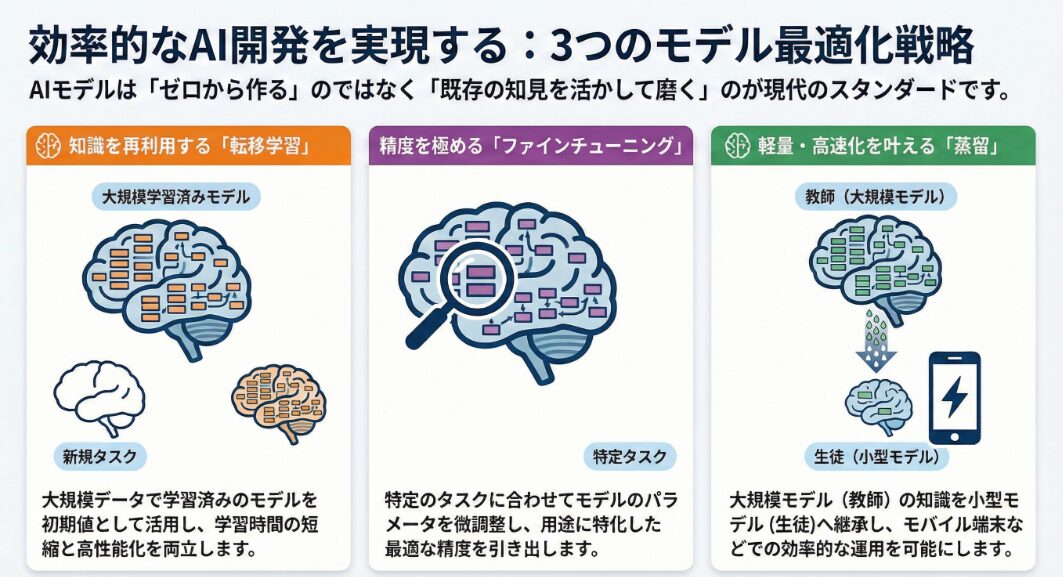
転移学習とは?事前学習済みモデルの活用
転移学習は、あるタスクで学習済みのモデルの知識を、別のタスクに適用する機械学習の手法です。このアプローチは、特に新しいタスクのデータが限られている場合に有効であり、モデルの学習時間を短縮し、性能を向上させることができます。
転移学習の核心は、事前学習済みモデルを活用することにあります。大規模なデータセットで学習されたモデルは、画像認識、自然言語処理など、さまざまなタスクに共通する特徴を捉えています。これらの特徴は、新しいタスクを学習する際の初期値として非常に有用です。例えば、ImageNetで学習された画像認識モデルは、新しい画像分類タスクにおいて、ランダムな初期値から学習するよりもはるかに早く収束し、高い精度を達成できます。
転移学習を活用することで、企業や研究者は、自社の特定のニーズに合わせてカスタマイズされたAIモデルを、より迅速かつ効率的に開発できます。これは、競争力を高め、イノベーションを加速するための重要な戦略となります。
ファインチューニングとは?モデルの微調整
ファインチューニングは、転移学習の一つの手法であり、事前学習済みのモデルを特定のタスクに合わせて微調整するプロセスです。このプロセスでは、事前学習で得られた知識を保持しつつ、新しいタスクのデータを使ってモデルのパラメータを更新します。ファインチューニングは、モデルの精度を向上させるために不可欠なステップであり、特に新しいタスクが事前学習タスクと類似している場合に効果的です。
ファインチューニングでは、モデルの全てのレイヤーを調整することも、一部のレイヤーのみを調整することも可能です。一般的には、最終層に近いレイヤーをより大きく調整し、初期のレイヤーはより小さく調整することが推奨されます。これは、初期のレイヤーがより一般的な特徴を捉えているのに対し、最終層に近いレイヤーがタスク固有の特徴を捉えているためです。ChatGPTの性能向上にも用いられていることからもその有用性が伺えます。
ファインチューニングは、モデルの性能を最大化するための重要なテクニックであり、AI開発において広く活用されています。
蒸留とは?軽量化と高速化
蒸留は、知識蒸留とも呼ばれ、大規模で複雑なモデル(教師モデル)の知識を、より小型で効率的なモデル(生徒モデル)に転送する技術です。この手法は、特にリソースが限られた環境(モバイルデバイスや組み込みシステムなど)でAIモデルを展開する際に役立ちます。
蒸留のプロセスでは、教師モデルの出力(ソフトターゲット)と生徒モデルの出力との間の差異を最小化するように、生徒モデルを学習させます。ソフトターゲットは、教師モデルが各クラスに対して予測した確率分布であり、ハードターゲット(正解ラベル)よりも多くの情報を含んでいます。これにより、生徒モデルは、教師モデルが学習した複雑な関係性をより効果的に学習できます。
蒸留は、モデルの精度を維持しながら、サイズを縮小し、推論速度を向上させるための強力なツールです。特に、大規模言語モデル(LLM)などの複雑なモデルを効率的に展開する上で重要な役割を果たします。
転移学習とファインチューニングの具体的な違い
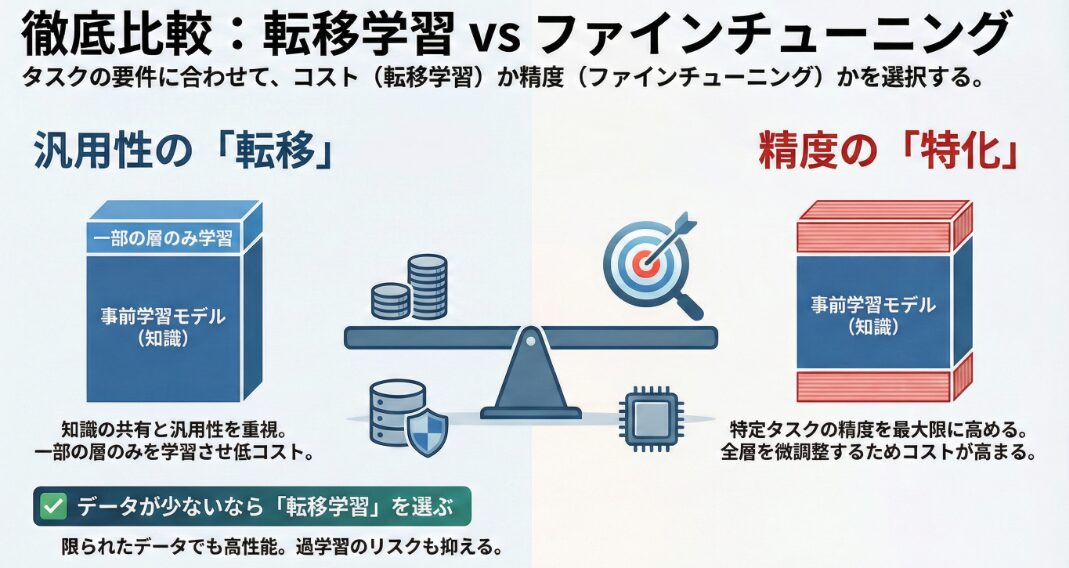
学習方法の違い:全体学習 vs 一部学習
転移学習とファインチューニングは、どちらも事前学習済みのモデルを利用する点では共通していますが、学習方法に重要な違いがあります。
転移学習では、事前学習済みモデルのパラメータを初期値として利用し、新しいタスクに合わせて一部または全体のパラメータを学習させます。この際、事前学習済みのパラメータを固定し、新しいタスクに合わせて追加したレイヤーのみを学習させることもあります。これにより、計算コストを削減し、過学習を防ぐことができます。
一方、ファインチューニングでは、通常、事前学習済みモデルのパラメータ全体を微調整します。新しいタスクのデータを使って、モデル全体のパラメータを少しずつ更新することで、モデルを特定のタスクに最適化します。ファインチューニングは、転移学習よりも計算コストがかかりますが、より高い精度を達成できる可能性があります。
どちらの手法を選択するかは、タスクの性質、データセットの規模、計算リソースなどの要因によって異なります。
データセットの規模:大規模 vs 小規模
転移学習とファインチューニングの選択は、利用可能なデータセットの規模に大きく依存します。一般的に、転移学習は大規模なデータセットで事前学習されたモデルを利用し、新しいタスクのデータセットが比較的小さい場合に有効です。事前学習済みモデルが持つ豊富な知識を活用することで、限られたデータでも高い性能を発揮できます。
一方、ファインチューニングは、転移学習で得られたモデルを、より小規模なデータセットで特定のタスクに特化して調整するために使用されます。この場合、事前学習済みモデルのパラメータを微調整することで、新しいタスクに対するモデルの適合度を高めます。ただし、データセットが小さすぎる場合、過学習のリスクが高まるため注意が必要です。
データセットの規模に応じて、転移学習とファインチューニングを適切に使い分けることが、成功への鍵となります。
目的の違い:汎用性 vs 特化性
転移学習とファインチューニングは、モデルの学習における目的が異なります。
転移学習は、異なるタスク間で知識を共有し、モデルの汎用性を高めることを目的とします。例えば、画像認識タスクで学習されたモデルを、物体検出タスクに応用することで、複数のタスクに対応できる汎用的なモデルを構築できます。このアプローチは、様々なタスクに共通する特徴を学習し、新しいタスクへの適応を容易にすることを重視します。
一方、ファインチューニングは、特定のタスクに対するモデルの精度を最大限に高めることを目的とします。事前学習済みモデルを特定のタスクのデータで微調整することで、そのタスクに特化した高性能なモデルを開発できます。このアプローチは、汎用性よりも特定のタスクにおける最高のパフォーマンスを追求します。
タスクの要件に応じて、転移学習とファインチューニングを適切に選択し、組み合わせることが重要です。
転移学習・ファインチューニングの活用事例
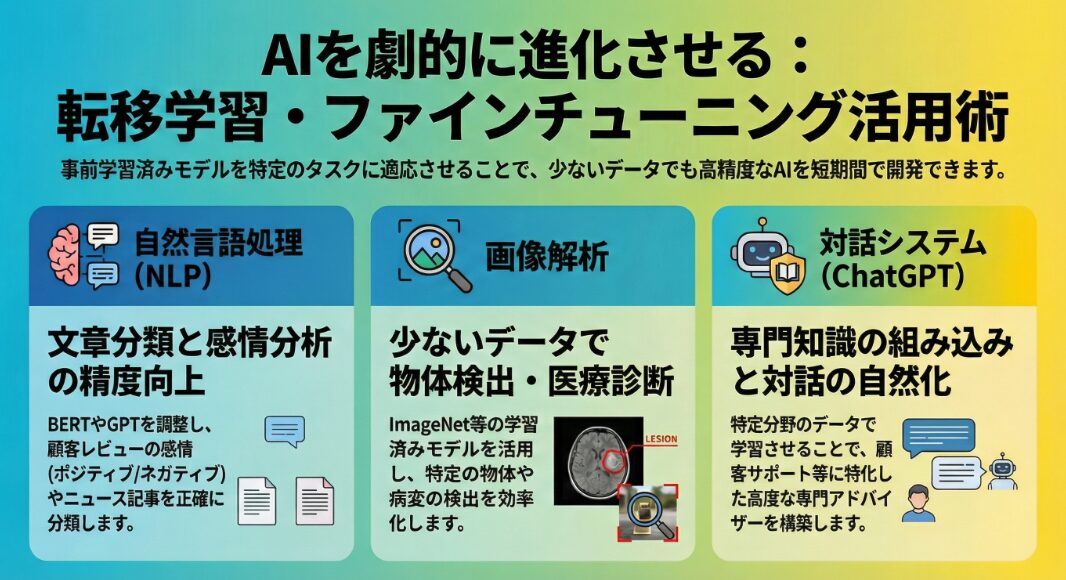
自然言語処理:文章分類、感情分析
自然言語処理(NLP)の分野では、転移学習とファインチューニングが広く活用されています。特に、文章分類や感情分析などのタスクにおいて、その効果が顕著に現れています。
BERTやGPTなどの事前学習済み言語モデルは、大量のテキストデータで学習されており、言語の構造や意味に関する豊富な知識を持っています。これらのモデルをファインチューニングすることで、特定の文章分類タスクや感情分析タスクにおいて、高い精度を実現できます。
例えば、顧客レビューの感情分析を行う場合、BERTをファインチューニングすることで、レビューテキストから顧客の感情(ポジティブ、ネガティブ、ニュートラルなど)を正確に識別できます。また、ニュース記事をカテゴリ分類する場合、GPTをファインチューニングすることで、記事の内容を正確に分類できます。
転移学習とファインチューニングは、NLPタスクにおけるモデル開発の効率性と精度を大幅に向上させる強力なツールです。
画像解析:物体検出、画像認識
画像解析の分野でも、転移学習とファインチューニングは重要な役割を果たしています。物体検出や画像認識などのタスクにおいて、これらの手法を活用することで、効率的に高精度なモデルを構築できます。
例えば、ImageNetで学習されたCNNモデルを転移学習し、特定の物体検出タスクに適用することで、少ないデータで高精度な物体検出器を開発できます。また、医療画像の解析において、転移学習を活用することで、病変の検出や診断支援を行うことができます。
転移学習は、画像解析タスクにおけるモデル開発の初期段階で、事前学習済みモデルの知識を活用することで、学習時間を短縮し、データ不足の問題を克服するのに役立ちます。その後、ファインチューニングを行うことで、特定のタスクに対するモデルの精度をさらに向上させることができます。
転移学習とファインチューニングは、画像解析の分野におけるAI技術の発展に大きく貢献しています。
ChatGPT:対話システムの改善
OpenAIのChatGPTは、大規模な言語モデルを基盤とした対話システムであり、その性能は転移学習とファインチューニングによって大きく向上しています。
ChatGPTは、まず大量のテキストデータで事前学習され、言語の構造や知識を獲得します。その後、特定のドメインやタスクに合わせてファインチューニングすることで、より自然で適切な対話を実現できます。例えば、顧客サポートに特化したChatGPTを開発する場合、顧客からの問い合わせデータでファインチューニングすることで、顧客のニーズに的確に対応できる対話システムを構築できます。
ファインチューニングは、ChatGPTの応答の質を向上させるだけでなく、特定のドメイン知識を組み込むためにも使用されます。これにより、ChatGPTは、特定の分野の専門家として、ユーザーに高度な情報やアドバイスを提供できるようになります。
転移学習とファインチューニングは、ChatGPTのような高度な対話システムの開発において、不可欠な技術となっています。
転移学習・ファインチューニングのメリット・デメリット
メリット:学習効率の向上、データ不足の克服
転移学習とファインチューニングは、AIモデルの開発において、多くのメリットをもたらします。最も重要なメリットの一つは、学習効率の向上です。事前学習済みモデルの知識を活用することで、ランダムな初期値から学習するよりも、はるかに早くモデルを収束させることができます。これにより、学習に必要な時間と計算コストを大幅に削減できます。
また、転移学習とファインチューニングは、データが不足している場合でも高精度なモデルを構築できるというメリットがあります。事前学習済みモデルは、大規模なデータセットで学習されているため、新しいタスクのデータが限られている場合でも、その知識を活用して高い性能を発揮できます。これは、特に医療画像解析や希少言語処理など、データ収集が困難な分野において非常に重要です。
転移学習とファインチューニングは、AIモデルの開発を加速し、より少ないリソースでより良い結果を得るための強力なツールです。
デメリット:過学習のリスク、モデルの複雑性
転移学習とファインチューニングは多くのメリットをもたらしますが、いくつかのデメリットも存在します。その一つが、過学習のリスクです。特に、ファインチューニングにおいて、データセットが小さい場合に、モデルが訓練データに過剰に適合し、未知のデータに対する汎化性能が低下する可能性があります。
また、転移学習によってモデルが複雑化し、解釈が難しくなる可能性があります。事前学習済みモデルは、大規模で複雑なアーキテクチャを持つことが多く、その知識を新しいタスクに転移する際に、モデルの複雑さを引き継いでしまうことがあります。モデルの解釈性が低いと、モデルの挙動を理解し、改善することが難しくなります。RAGやLoRAといった技術も検討しましょう。
これらのデメリットを克服するためには、適切な正則化手法やデータ拡張手法を適用し、モデルの複雑さを制御することが重要です。また、モデルの解釈性を高めるための研究も進められています。
転移学習・ファインチューニングを成功させるためのポイント
適切な事前学習済みモデルの選択
転移学習とファインチューニングを成功させるためには、タスクに適した事前学習済みモデルを選択することが非常に重要です。モデルのアーキテクチャ、学習データ、タスクとの関連性を慎重に考慮する必要があります。
例えば、画像認識タスクであれば、ImageNetで学習されたCNNモデルが適している可能性があります。自然言語処理タスクであれば、BERTやGPTなどの事前学習済み言語モデルが適しているでしょう。また、特定のドメインに特化したタスクであれば、そのドメインのデータで学習されたモデルを選択することが望ましいです。
適切な事前学習済みモデルを選択することで、学習時間を短縮し、モデルの性能を向上させることができます。モデル選択の際には、公開されているベンチマークデータや研究論文を参考にすると良いでしょう。
適切なファインチューニング戦略の策定
ファインチューニングを成功させるためには、適切なファインチューニング戦略を策定することが重要です。学習率、バッチサイズ、エポック数などのハイパーパラメータを適切に設定し、データ拡張などのテクニックを活用することで、モデルの性能を最大限に引き出すことができます。
学習率は、モデルの学習速度を制御する重要なパラメータであり、小さすぎると学習が進まず、大きすぎると学習が不安定になる可能性があります。バッチサイズは、一度に学習するデータの数を制御するパラメータであり、大きすぎるとメモリ不足になる可能性があり、小さすぎると学習が不安定になる可能性があります。
データ拡張は、訓練データの量を増やすためのテクニックであり、過学習を防ぐのに役立ちます。画像データの場合、回転、反転、ズームなどの操作を適用することで、データを拡張できます。テキストデータの場合、同義語置換やランダム挿入などの操作を適用することで、データを拡張できます。
これらのハイパーパラメータやテクニックを適切に設定し、組み合わせることで、ファインチューニングの効果を最大化することができます。
十分な評価と検証
モデルの性能を評価するために、適切な評価指標を選択し、十分な検証を行うことが重要です。評価指標は、タスクの種類に応じて適切に選択する必要があります。例えば、分類タスクであれば、正解率、適合率、再現率、F1スコアなどが一般的な評価指標です。回帰タスクであれば、平均二乗誤差、平均絶対誤差などが一般的な評価指標です。
検証は、モデルの汎化性能を評価するために不可欠です。交差検証やホールドアウト検証などの手法を活用することで、モデルが未知のデータに対してどの程度うまく機能するかを評価できます。交差検証は、データを複数のグループに分割し、各グループを検証データとして使用し、残りのグループを訓練データとして使用する方法です。ホールドアウト検証は、データを訓練データと検証データに分割し、訓練データでモデルを学習し、検証データでモデルの性能を評価する方法です。
これらの評価と検証を十分に行うことで、モデルの性能を客観的に評価し、改善点を見つけることができます。
まとめ:転移学習とファインチューニングを使いこなそう
転移学習とファインチューニングは、AIモデルの学習効率を向上させるための強力なツールです。これらの手法を活用することで、より少ないデータと計算リソースで、より高度なAIシステムを開発できます。
転移学習は、大規模なデータセットで事前学習されたモデルの知識を、別のタスクに適用する手法であり、特に新しいタスクのデータが限られている場合に有効です。ファインチューニングは、転移学習で得られたモデルを、特定のタスクに合わせて微調整するプロセスであり、モデルの精度を向上させるために不可欠です。
それぞれの特徴を理解し、タスクやデータセットに合わせて適切に活用することで、AI開発の可能性を広げることができます。これらの技術を積極的に活用し、AIの未来を切り拓いていきましょう。










