
AI技術の進化は目覚ましいですが、リアルタイムでの応答が求められる場面では、レイテンシー(遅延)が大きな課題となります。本記事では、AIのレイテンシー問題を深掘りし、その原因と具体的な対策について解説します。
AIレイテンシーとは?なぜ重要なのか
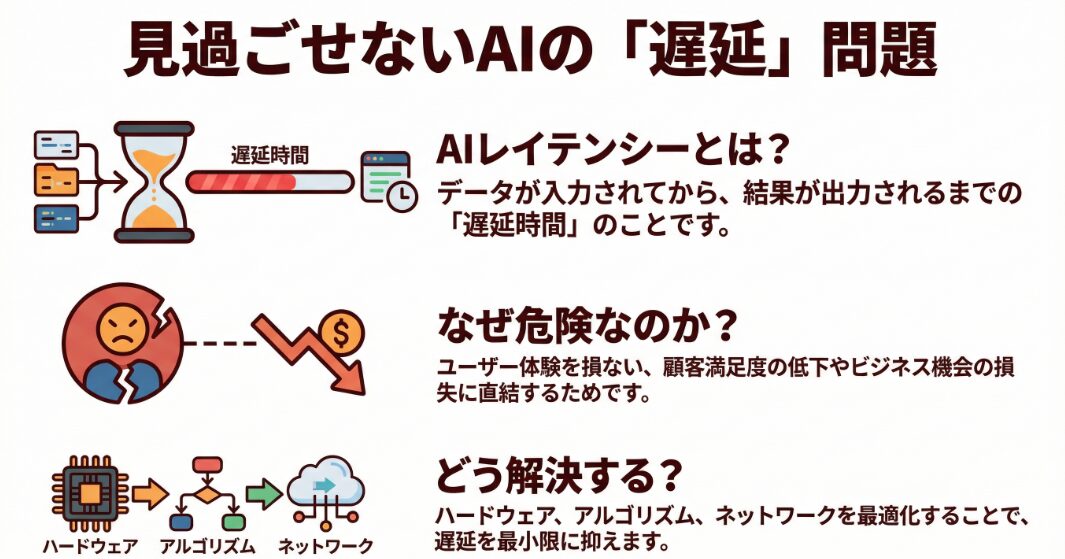
レイテンシーの定義と影響
AIにおけるレイテンシーとは、入力されたデータが処理され、
結果が出力されるまでの遅延時間のことです。この遅延時間が長ければ長いほど、
リアルタイム性が損なわれるため、ユーザー体験に悪影響を及ぼします。
特に、インタラクティブなアプリケーションやリアルタイムな意思決定が求められるシステムにおいては、
レイテンシーは重大な問題となります。
レイテンシーは、単に処理速度が遅いというだけでなく、
ビジネスの機会損失や顧客満足度の低下にもつながる可能性があります。
例えば、オンラインゲームでは、レイテンシーが高いとプレイヤーの操作に対する反応が遅れ、
ゲーム体験が著しく損なわれます。また、金融取引においては、
わずかな遅延が大きな損失につながることもあります。
したがって、AIシステムを設計・開発する際には、
レイテンシーを最小限に抑えるための対策を講じることが不可欠です。
ハードウェアの最適化、アルゴリズムの改善、ネットワークの高速化など、
様々なアプローチを組み合わせることで、低レイテンシーなAIシステムを実現し、
ビジネス価値を最大化することができます。
リアルタイムAIの重要性

リアルタイムAIは、文字通り、データを即座に処理し、
リアルタイムで応答を提供するAIシステムのことです。
自動運転車、金融取引システム、医療診断ツールなど、
多くの重要なアプリケーションにおいて、リアルタイムAIは不可欠な要素となっています。
自動運転車の場合、センサーから収集されたデータを瞬時に分析し、
車両の制御をリアルタイムで行う必要があります。わずかな遅延でも、
事故につながる可能性があるため、極めて低いレイテンシーが求められます。
金融取引においては、市場の変動に迅速に対応し、
最適なタイミングで取引を実行するために、リアルタイムAIが活用されています。
不正検知システムも、リアルタイムで異常なパターンを検出し、
詐欺行為を未然に防ぐために、低レイテンシーであることが重要です。
医療分野では、患者のバイタルデータをリアルタイムでモニタリングし、
異常が発生した場合に迅速にアラートを発するシステムや、
画像診断において、医師の診断を支援するAIツールなどが、
リアルタイムAIの重要な応用例となっています。
これらの例からもわかるように、リアルタイムAIは、
人々の生活や社会に大きな影響を与える可能性を秘めており、
その重要性はますます高まっています。
レイテンシーがビジネスに与える影響
AIのレイテンシーは、ビジネスの様々な側面に影響を及ぼします。
顧客体験、業務効率、意思決定の質、そして最終的な収益にまで、
その影響は及びます。
顧客体験において、レイテンシーは直接的な影響を与えます。
例えば、チャットボットやバーチャルアシスタントなどの会話型AIサービスでは、
応答速度が遅いと、ユーザーは不満を感じ、サービスを利用するのをためらう可能性があります。
顧客は、迅速かつスムーズな対応を期待しており、
レイテンシーが高いと、その期待を裏切ることになります。
業務効率の面では、レイテンシーは従業員の生産性を低下させる可能性があります。
例えば、データ分析ツールやレポート作成ツールなど、
AIを活用した業務システムにおいて、処理速度が遅いと、
従業員は作業を中断せざるを得なくなり、業務の遅延につながります。
意思決定においては、レイテンシーは迅速かつ正確な判断を妨げる可能性があります。
例えば、リアルタイムで市場データを分析し、
投資判断を行うAIシステムにおいて、レイテンシーが高いと、
最適なタイミングを逃し、損失を被る可能性があります。
これらの影響を総合的に考えると、AIのレイテンシーは、
ビジネスの成功を左右する重要な要素であることがわかります。
企業は、レイテンシーを最小限に抑えるための対策を講じ、
競争優位性を確立する必要があります。
レイテンシーの原因を特定する
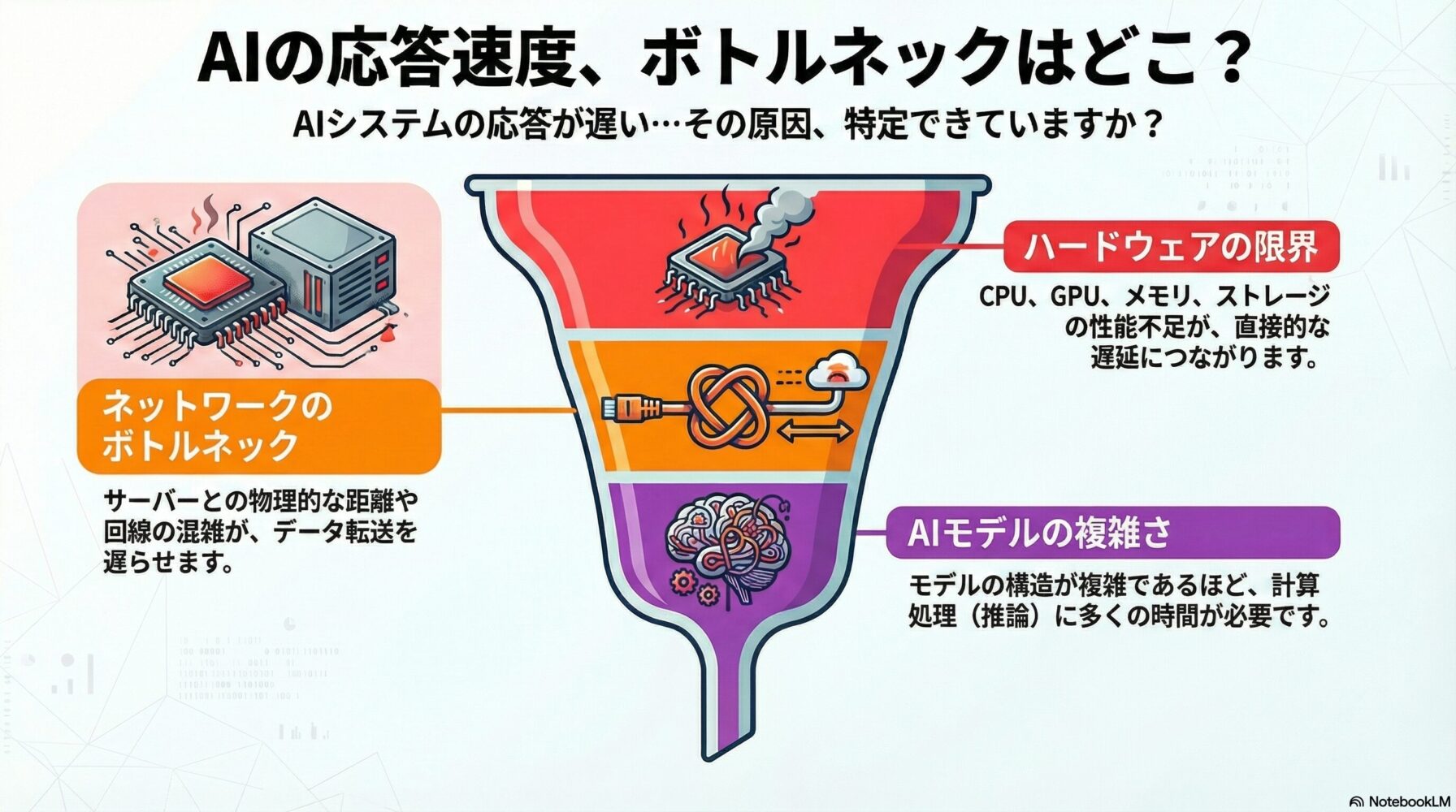
ハードウェアの制約
AIシステムのレイテンシーは、ハードウェアの性能に大きく依存します。
CPU、GPU、メモリ、ストレージなど、様々なハードウェアコンポーネントが、
レイテンシーに影響を与える可能性があります。
CPUは、AIモデルの推論処理の中核を担う部分であり、
CPUの処理能力が低いと、推論に時間がかかり、レイテンシーが増加します。
特に、複雑なモデルや大規模なデータセットを扱う場合は、
高性能なCPUが不可欠です。
GPUは、並列処理に特化したプロセッサであり、
AIモデルの学習や推論を高速化するために広く利用されています。
GPUの性能が低いと、特に深層学習モデルの処理において、
レイテンシーが顕著に増加します。
メモリは、AIモデルやデータを一時的に保存するために使用されます。
メモリ容量が不足すると、ディスクからのデータの読み込みが発生し、
レイテンシーが増加します。十分なメモリ容量を確保することが重要です。
ストレージは、AIモデルやデータを永続的に保存するために使用されます。
ストレージのアクセス速度が遅いと、データの読み込みに時間がかかり、
レイテンシーが増加します。SSDなどの高速なストレージを使用することが推奨されます。
これらのハードウェアコンポーネントの性能を最適化することで、
AIシステムのレイテンシーを大幅に削減することができます。
ネットワークの遅延
ネットワークの遅延は、AIシステムのレイテンシーに大きな影響を与える要因の一つです。
データがクライアントからサーバーに送信され、
サーバーで処理された結果がクライアントに返送されるまでに時間がかかると、
レイテンシーが増加します。
ネットワーク遅延の原因は様々ですが、主なものとしては、
物理的な距離、ネットワークの混雑、ルーターやスイッチなどのネットワーク機器の性能などが挙げられます。
物理的な距離が長いほど、データが伝送されるのに時間がかかり、レイテンシーが増加します。
特に、海外のサーバーを利用する場合は、
ネットワーク遅延が大きくなる傾向があります。
ネットワークの混雑も、レイテンシーを増加させる要因となります。
ネットワークの使用量が多い時間帯や、特定の地域でアクセスが集中する場合などに、
ネットワークが混雑し、データの伝送速度が低下します。
ルーターやスイッチなどのネットワーク機器の性能が低い場合も、
レイテンシーが増加する可能性があります。
これらの機器は、ネットワーク上のデータを効率的にルーティングするために使用されますが、
性能が低いと、処理に時間がかかり、遅延が発生します。
ネットワーク遅延を削減するためには、
地理的に近いサーバーを利用する、CDN(コンテンツデリバリーネットワーク)を活用する、
ネットワーク機器を高性能なものに交換するなどの対策が有効です。
AIモデルの複雑さ
AIモデルの複雑さは、レイテンシーに大きな影響を与える要因の一つです。
複雑なモデルは、より多くの計算リソースを必要とし、
推論に時間がかかるため、レイテンシーが増加します。
モデルの複雑さは、モデルの構造、パラメータ数、
使用する演算の種類などによって決まります。
例えば、深層学習モデルは、多くの層とニューロンを持つ複雑な構造をしており、
大量のパラメータを持っています。そのため、深層学習モデルは、
比較的単純なモデルに比べて、推論に時間がかかる傾向があります。
また、モデルが使用する演算の種類も、レイテンシーに影響を与えます。
例えば、行列演算や畳み込み演算などの複雑な演算は、
単純な演算に比べて、計算に時間がかかります。
AIモデルの複雑さを削減するためには、モデルの軽量化や最適化が有効です。
モデルの量子化、プルーニング、知識蒸留などの手法を用いることで、
モデルのサイズを縮小し、推論速度を向上させることができます。
また、モデルの構造を簡略化したり、より効率的な演算を使用したりすることも、
レイテンシーの削減に役立ちます。
レイテンシーを削減するための実践的戦略
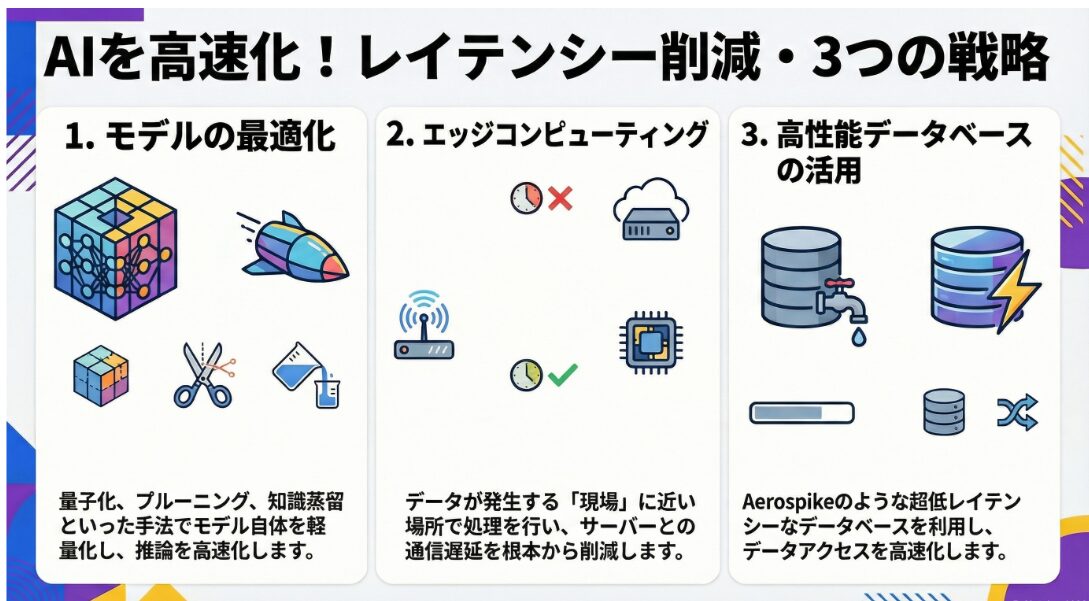
モデルの最適化
AIモデルの最適化は、レイテンシーを削減するための最も重要な戦略の一つです。
モデルの最適化には、様々な手法がありますが、
主なものとしては、モデルの量子化、プルーニング、知識蒸留などが挙げられます。
モデルの量子化は、モデルのパラメータの精度を下げることで、
モデルサイズを縮小し、推論速度を向上させる手法です。
例えば、32ビット浮動小数点数で表現されたパラメータを、
8ビット整数で表現することで、モデルサイズを1/4に削減することができます。
モデルのプルーニングは、モデルの重要度の低いパラメータを削除することで、
モデルサイズを縮小し、推論速度を向上させる手法です。
例えば、ニューラルネットワークにおいて、出力にほとんど影響を与えないニューロンや結合を削除することで、
モデルを簡略化することができます。
知識蒸留は、大規模なモデル(教師モデル)から、
軽量なモデル(生徒モデル)に知識を転送する手法です。
生徒モデルは、教師モデルの出力を模倣するように学習されるため、
教師モデルと同等の性能を維持しながら、モデルサイズを縮小することができます。
これらのモデル最適化手法を組み合わせることで、
AIモデルのレイテンシーを大幅に削減し、リアルタイム性を向上させることができます。
エッジコンピューティングの活用
エッジコンピューティングは、データセンターなどの集中型サーバーではなく、
ネットワークのエッジに近い場所でデータ処理を行う技術です。
AI推論をエッジデバイスで行うことで、ネットワーク遅延を削減し、
リアルタイム性を向上させることができます。
エッジコンピューティングの利点は、主に以下の3点です。
1.ネットワーク遅延の削減:データをサーバーに送信する必要がないため、
ネットワーク遅延を大幅に削減できます。
2.帯域幅の節約:処理済みのデータのみをサーバーに送信するため、
ネットワークの帯域幅を節約できます。
3.プライバシーの保護:データをローカルで処理するため、
プライバシーを保護することができます。
エッジコンピューティングは、自動運転車、IoTデバイス、
スマートシティなど、様々な分野で活用されています。
例えば、自動運転車では、車載カメラで撮影した画像をリアルタイムで分析し、
歩行者や障害物を検知する必要があります。
エッジコンピューティングを活用することで、ネットワーク遅延を最小限に抑え、
安全な運転を支援することができます。
IoTデバイスでは、センサーから収集したデータをローカルで処理し、
異常を検知したり、機器の制御を行ったりすることができます。
エッジコンピューティングを活用することで、リアルタイムな応答が可能になり、
効率的な運用を実現することができます。
Aerospikeデータベースの活用
Aerospikeは、リアルタイムデータ処理に特化した高性能なNoSQLデータベースです。
従来のデータベースに比べて、高速なデータアクセスと低レイテンシーを実現できるため、
AIシステムのレイテンシー削減に貢献することができます。
Aerospikeの主な特徴は以下の通りです。
1.インメモリとフラッシュストレージのハイブリッドアーキテクチャ:
頻繁にアクセスされるデータはメモリに、それ以外のデータはフラッシュストレージに保存することで、
高速なデータアクセスと大容量のデータストレージを両立しています。
2.分散アーキテクチャ:データを複数のノードに分散して保存することで、
高いスケーラビリティと可用性を実現しています。
3.自動シャーディング:データを自動的に分割し、複数のノードに分散することで、
データ量の増加に対応することができます。
4.リアルタイムデータ処理:高速なデータアクセスと低レイテンシーを実現することで、
リアルタイムなデータ処理を可能にします。
Aerospikeは、金融取引、広告配信、ゲームなど、
リアルタイム性が求められる様々な分野で活用されています。
例えば、金融取引システムでは、市場の変動に迅速に対応し、
最適なタイミングで取引を実行するために、Aerospikeが活用されています。
広告配信システムでは、ユーザーの行動履歴をリアルタイムで分析し、
最適な広告を配信するために、Aerospikeが活用されています。
低レイテンシーAIの未来展望
ハードウェアの進化
AIの進化とともに、ハードウェアの進化も加速しています。
より高速で効率的なAIチップの開発が進み、
レイテンシー問題は徐々に解消されていくと予想されます。
特に、GPU(GraphicsProcessing Unit)やTPU(Tensor ProcessingUnit)などの
専用ハードウェアの進化は目覚ましいものがあります。
GPUは、並列処理に特化したプロセッサであり、
AIモデルの学習や推論を高速化するために広く利用されています。
近年、GPUの性能は飛躍的に向上しており、
より複雑なAIモデルをより高速に処理することが可能になっています。
TPUは、Googleが開発したAI専用のプロセッサであり、
深層学習モデルの学習や推論に最適化されています。
TPUは、GPUよりもさらに高い性能を発揮し、
大規模なAIモデルを高速に処理することができます。
また、量子コンピュータなどの新しいハードウェア技術も、
AIのレイテンシー問題を解決する可能性を秘めています。
量子コンピュータは、従来のコンピュータとは異なる原理で動作し、
特定の問題を非常に高速に解決することができます。
これらのハードウェアの進化により、AIの処理能力はますます向上し、
レイテンシー問題は徐々に解消されていくと期待されます。
AIモデルの軽量化
AIモデルの軽量化は、低レイテンシーAIを実現するための重要な要素です。
より少ない計算リソースで同等の性能を発揮できるAIモデルの研究が進み、
エッジデバイスでも高度なAI処理が可能になるでしょう。
モデルの軽量化には、様々な手法がありますが、
主なものとしては、モデルの量子化、プルーニング、知識蒸留などが挙げられます。
モデルの量子化は、モデルのパラメータの精度を下げることで、
モデルサイズを縮小し、推論速度を向上させる手法です。
モデルのプルーニングは、モデルの重要度の低いパラメータを削除することで、
モデルサイズを縮小し、推論速度を向上させる手法です。
知識蒸留は、大規模なモデル(教師モデル)から、
軽量なモデル(生徒モデル)に知識を転送する手法です。
これらのモデル軽量化手法に加えて、
より効率的なモデルアーキテクチャの研究も進んでいます。
例えば、MobileNetやShuffleNetなどのモバイル向けに最適化されたモデルは、
少ない計算リソースで高い性能を発揮することができます。
AIモデルの軽量化により、エッジデバイスでも高度なAI処理が可能になり、
リアルタイムAIの応用範囲がさらに広がると期待されます。
まとめ
AIのレイテンシー問題は、リアルタイム性を重視する分野において避けて通れない課題です。
レイテンシーは、顧客体験、業務効率、意思決定の質など、
ビジネスの様々な側面に影響を及ぼします。
レイテンシーの原因は、ハードウェアの制約、ネットワークの遅延、
AIモデルの複雑さなど、多岐にわたります。
レイテンシーを削減するためには、ハードウェア、ソフトウェア、
ネットワークの各側面から最適化を図る必要があります。
具体的には、モデルの量子化やプルーニングなどのモデル最適化手法、
エッジコンピューティングの活用、Aerospikeのような高性能データベースの活用などが有効です。
ハードウェアの進化やAIモデルの軽量化が進むことで、
レイテンシー問題は徐々に解消されていくと予想されます。
低レイテンシーAIを実現することで、自動運転、金融取引、医療診断など、
リアルタイム性が求められる分野において、新たなビジネスチャンスが生まれるでしょう。
企業は、レイテンシー問題に積極的に取り組み、
低レイテンシーAIの実現を目指すことで、競争優位性を確立し、
ビジネスの可能性を大きく広げることができます。










