

AIのハルシネーションは、まるでAIが見ているかのような幻覚です。この記事では、ハルシネーションの種類、原因、具体的な事例、そしてその対策までをわかりやすく解説します。生成AIを安全に活用するために、ハルシネーションについて深く理解しましょう。
ハルシネーションとは何か?

ハルシネーションの定義と意味
ハルシネーションとは、AI、特に大規模言語モデルが、事実に基づかない、または意味のない情報を生成する現象を指します。まるで幻覚を見ているかのように、もっともらしい嘘をつくことがあります。この現象は、AIが学習データに基づいてテキストを生成する過程で、誤ったパターンを学習したり、存在しない情報を創造したりすることで発生します。
ハルシネーションは、AIの信頼性を大きく揺るがす要因となり得ます。特に、重要な意思決定をAIに委ねる場合、ハルシネーションによって誤った情報に基づいて判断が下されるリスクがあります。そのため、AI開発者はハルシネーションを抑制するための様々な対策を講じています。具体的には、学習データの質を向上させたり、モデルの構造を改良したり、出力結果を検証する仕組みを導入したりするなどの取り組みが行われています。
ハルシネーションは、AIの進化とともに常に存在する課題であり、完全に排除することは難しいと考えられています。しかし、そのリスクを理解し、適切な対策を講じることで、AIをより安全かつ効果的に活用することができます。今後のAI研究においては、ハルシネーションのメカニズム解明と、それを抑制するための技術開発がますます重要になっていくでしょう。
AIにおけるハルシネーションの種類
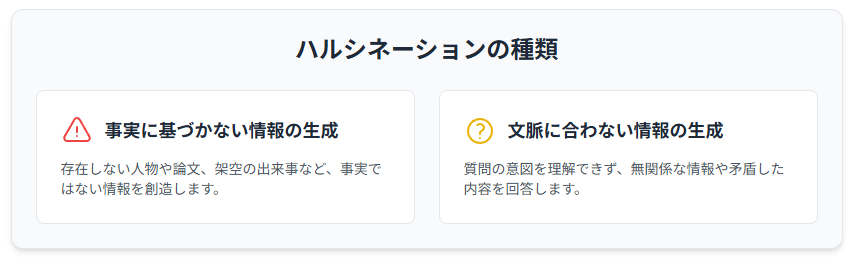
AIのハルシネーションには、大きく分けて「事実に基づかない情報の生成」と「文脈に合わない情報の生成」の2種類があります。前者は、存在しない情報を生成したり、誤った情報を提示したりするもので、後者は、質問や指示とは無関係な情報を生成するものです。事実に基づかない情報の生成は、AIが学習データに存在しない情報を創造したり、既存の情報を誤って解釈したりすることで発生します。例えば、存在しない人物の名前を挙げたり、架空の出来事について語ったりすることがあります。
一方、文脈に合わない情報の生成は、AIが質問や指示の意図を正しく理解できずに、不適切な情報を生成するものです。例えば、質問とは全く関係のない情報を提示したり、矛盾する情報を提示したりすることがあります。これらのハルシネーションは、AIの利用目的に応じて、様々な問題を引き起こす可能性があります。例えば、顧客対応AIが事実に基づかない情報を顧客に提供した場合、企業の信頼を損なう可能性があります。また、医療診断AIが誤った情報を提示した場合、患者の健康を害する可能性があります。
そのため、AI開発者は、ハルシネーションの種類に応じて、適切な対策を講じる必要があります。事実に基づかない情報の生成に対しては、学習データの質を向上させたり、知識ベースを拡充したりする対策が有効です。一方、文脈に合わない情報の生成に対しては、AIが質問や指示の意図をより正確に理解できるように、自然言語処理技術を改良する必要があります。
ハルシネーションがもたらす影響
ハルシネーションは、AIの信頼性を損ない、誤った意思決定につながる可能性があります。特に、ビジネスや医療などの分野では、深刻な問題を引き起こすリスクがあります。AIが生成した情報が誤っている場合、それに基づいて下された意思決定も誤ったものになる可能性があります。例えば、AIが生成した市場予測に基づいて投資判断を行った場合、予測が誤っていれば、大きな損失を被る可能性があります。
また、ハルシネーションは、AIの利用に対するユーザーの信頼を損なう可能性があります。AIが生成した情報が頻繁に誤っている場合、ユーザーはAIの利用をためらうようになり、AIの普及を妨げる可能性があります。さらに、ハルシネーションは、AIの倫理的な問題を引き起こす可能性もあります。AIが差別的な情報や偏った情報を生成した場合、社会的な不公平を助長する可能性があります。例えば、採用AIが特定の属性を持つ応募者を不当に不利に扱うような情報を提供した場合、差別問題に発展する可能性があります。
このように、ハルシネーションは、AIの社会実装において、様々な負の影響をもたらす可能性があります。そのため、AI開発者は、ハルシネーションのリスクを十分に認識し、その対策に真剣に取り組む必要があります。また、AIの利用者は、AIが生成した情報を鵜呑みにせず、常に批判的な視点を持って検証する必要があります。
ハルシネーションはなぜ起こるのか?
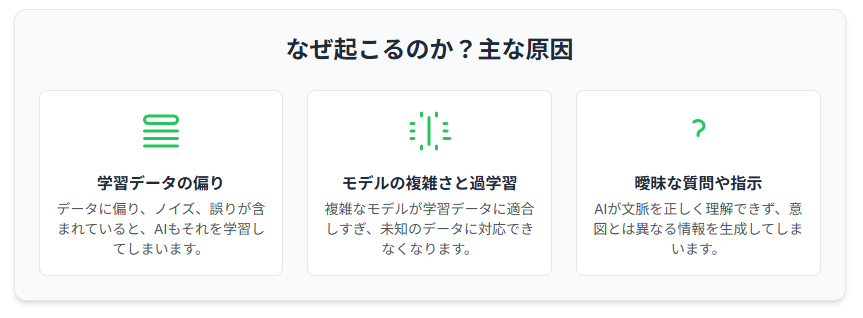
学習データの偏り
AIの学習データに偏りがある場合、ハルシネーションが発生しやすくなります。例えば、特定の情報源に偏ったデータで学習させた場合、その情報源に都合の良い情報を生成する可能性が高まります。AIは、学習データからパターンを学習し、それを基に新しい情報を生成します。そのため、学習データに偏りがあると、AIもその偏りを学習してしまい、偏った情報を生成するようになるのです。例えば、ある特定の政治的イデオロギーに関する情報ばかりで学習させたAIは、そのイデオロギーに偏った情報を生成する可能性が高くなります。
また、学習データに含まれるノイズや誤った情報も、ハルシネーションの原因となります。AIは、学習データに含まれる誤った情報も学習してしまうため、それを基に誤った情報を生成してしまうのです。さらに、学習データが不足している場合も、ハルシネーションが発生しやすくなります。学習データが不足していると、AIは十分なパターンを学習できず、不確かな情報を生成してしまう可能性があります。
したがって、AI開発者は、学習データの質と量を十分に考慮し、偏りのない、正確なデータを用意する必要があります。また、学習データの偏りを検出し、修正するための技術も開発されています。これらの技術を活用することで、ハルシネーションのリスクを低減することができます。
モデルの複雑さと過学習
複雑すぎるモデルは、過学習(学習データに過剰に適合してしまうこと)を起こしやすく、結果としてハルシネーションにつながることがあります。過学習とは、AIモデルが学習データに対して過剰に適合してしまい、未知のデータに対する汎化能力が低下する現象のことです。過学習を起こしたAIモデルは、学習データに含まれるノイズや誤った情報も学習してしまうため、ハルシネーションを起こしやすくなります。
モデルの複雑さは、モデルのパラメータ数や層の数などで測ることができます。パラメータ数が多すぎるモデルや、層が深すぎるモデルは、複雑なモデルであると言えます。このような複雑なモデルは、表現力が高く、学習データに対して高い精度を達成することができますが、同時に過学習のリスクも高くなります。
過学習を防ぐためには、モデルの複雑さを適切に調整する必要があります。例えば、モデルのパラメータ数を減らしたり、層の数を浅くしたりすることで、モデルの複雑さを低減することができます。また、正則化という手法を用いることで、過学習を抑制することもできます。正則化とは、モデルの学習時に、モデルの複雑さに対するペナルティを課すことで、モデルが過剰に学習データに適合するのを防ぐ手法です。L1正則化やL2正則化など、様々な種類の正則化手法が存在します。
曖昧な質問や指示
質問や指示が曖昧な場合、AIは文脈を正しく理解できず、不適切な情報を生成することがあります。AIは、人間のように柔軟な思考を持つことができないため、曖昧な表現や指示を正確に解釈することが苦手です。そのため、質問や指示があいまいだと、AIは質問者の意図を誤解し、期待とは異なる情報を生成してしまうことがあります。例えば、「最近話題の映画について教えて」という質問は、AIにとって曖昧な質問です。「最近」とはいつ頃を指すのか、「話題」とはどのような基準で判断するのか、といった点が不明確です。このような質問に対して、AIは、質問者の意図とは異なる映画を紹介したり、古い映画を紹介したりする可能性があります。
質問や指示を明確にするためには、具体的な情報を提供するように心がける必要があります。例えば、「2023年に公開された、興行収入が10億円を超えた映画について教えて」という質問は、より明確な質問です。この質問に対して、AIは、質問者の意図に沿った映画を紹介する可能性が高くなります。また、質問や指示を構造化することも有効です。例えば、箇条書きで質問事項を整理したり、質問の目的を明確に伝えたりすることで、AIは質問者の意図をより正確に理解することができます。
ハルシネーションの事例
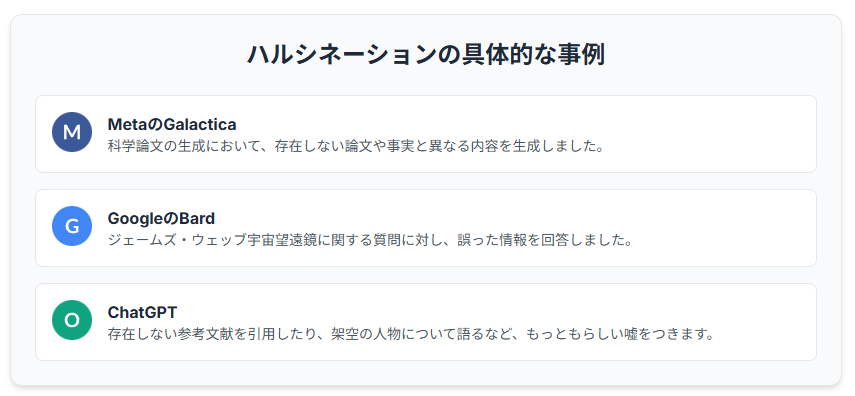
MetaのGalacticaの事例
Meta(Facebook)の科学用大規模言語モデル「Galactica」は、科学論文の生成において、事実とは異なる内容や、存在しない論文情報を生成するハルシネーションを起こしました。Galacticaは、科学論文の作成を支援することを目的として開発されたAIモデルでしたが、公開後すぐに、そのハルシネーションの多さが問題視されました。例えば、存在しない論文の著者やタイトルを生成したり、科学的な根拠のない主張をしたりするなどの事例が報告されました。Galacticaが生成した情報は、一見するともっともらしい科学論文のように見えるため、専門家が見ても誤りを見抜くのが難しい場合がありました。
この問題を受けて、MetaはGalacticaの公開を一時停止し、モデルの改善に取り組むことになりました。Galacticaの事例は、大規模言語モデルが、専門的な分野においてもハルシネーションを起こす可能性があることを示唆しています。また、AIが生成した情報を無批判に信じることの危険性を示唆する事例でもあります。Galacticaの事例から、AI開発者は、モデルの性能だけでなく、その信頼性や安全性を十分に考慮する必要があるという教訓を得ることができます。
Google Bardの事例
Googleの会話型AIサービス「Bard」は、発表当初、ジェームズ・ウェッブ宇宙望遠鏡に関する質問に対し、誤った情報を回答するハルシネーションを起こし、話題となりました。Bardは、Googleが開発した大規模言語モデルLaMDAを基盤とするAIサービスで、自然な会話を通じてユーザーの質問に答えたり、様々なタスクを実行したりすることができます。しかし、発表時のデモンストレーションにおいて、Bardは、ジェームズ・ウェッブ宇宙望遠鏡が初めて太陽系外惑星の写真を撮影したという誤った情報を回答しました。実際には、ジェームズ・ウェッブ宇宙望遠鏡は太陽系外惑星の写真を撮影していません。
この誤った情報は、すぐにSNS上で拡散され、Googleの株価が一時的に下落するなどの影響が出ました。Bardの事例は、AIが生成する情報が、企業の評判や株価に大きな影響を与える可能性があることを示唆しています。また、AIのハルシネーションが、企業の信頼性を損なう可能性があることを示す事例でもあります。Googleは、Bardのハルシネーション問題を真摯に受け止め、モデルの改善に取り組んでいます。Bardの事例から、AI開発者は、モデルの性能だけでなく、その正確性や信頼性を十分に考慮する必要があるという教訓を得ることができます。
ChatGPTの事例
ChatGPTは、もっともらしい嘘をつくことで知られています。例えば、存在しない参考文献を引用したり、架空の人物について語ったりすることがあります。ChatGPTは、OpenAIが開発した大規模言語モデルで、自然な文章を生成する能力が高く、様々なタスクに活用されています。しかし、ChatGPTは、ハルシネーションを起こしやすく、誤った情報や存在しない情報を生成することがあります。例えば、ChatGPTは、存在しない参考文献を引用したり、架空の人物について語ったりすることがあります。これらの情報は、一見するともっともらしく見えるため、注意が必要です。
ChatGPTのハルシネーションは、様々な問題を引き起こす可能性があります。例えば、ChatGPTが生成した情報を基にレポートを作成した場合、誤った情報が拡散される可能性があります。また、ChatGPTが生成した情報を基に意思決定を行った場合、誤った判断をしてしまう可能性があります。ChatGPTの利用者は、ChatGPTが生成した情報を鵜呑みにせず、必ず自分で情報を検証する必要があります。OpenAIは、ChatGPTのハルシネーション問題を認識しており、モデルの改善に取り組んでいます。ChatGPTの事例から、AIの利用者は、AIが生成した情報を批判的に評価する能力を身につける必要があるという教訓を得ることができます。
ハルシネーションへの対策
ファインチューニングによる改善
特定のタスクやドメインに特化したデータでAIモデルを再学習させることで、ハルシネーションを抑制できます。これをファインチューニングと呼びます。ファインチューニングは、大規模言語モデルを特定の用途に合わせて最適化するために用いられる手法で、ハルシネーションの抑制にも効果を発揮します。例えば、医療分野に特化したAIモデルを開発する場合、医療に関する専門的なデータを用いてファインチューニングを行うことで、医療に関するハルシネーションのリスクを低減することができます。
ファインチューニングを行う際には、質の高いデータを用意することが重要です。不正確なデータや偏ったデータを用いてファインチューニングを行うと、かえってハルシネーションを悪化させる可能性があります。また、ファインチューニングの際には、モデルのパラメータを適切に調整する必要があります。パラメータの調整が不適切だと、過学習を引き起こし、ハルシネーションを誘発する可能性があります。ファインチューニングは、AIモデルの性能を向上させるための強力な手法ですが、適切な知識と経験が必要です。ファインチューニングを行う際には、専門家の指導を受けることをお勧めします。
AIの出力を検証する
AIが生成した情報を鵜呑みにせず、必ず人間の目で検証することが重要です。特に、重要な意思決定に関わる場合は、専門家の意見を参考にしましょう。AIは、あくまでツールであり、人間の判断を代替するものではありません。AIが生成した情報は、常に誤りを含む可能性があることを認識しておく必要があります。AIが生成した情報を検証する際には、複数の情報源を参照し、情報の正確性を確認することが重要です。また、AIが生成した情報の根拠を調べ、その妥当性を評価することも重要です。
特に、重要な意思決定に関わる場合は、AIが生成した情報を鵜呑みにせず、必ず専門家の意見を参考にしましょう。専門家は、AIが生成した情報の誤りを見抜くことができ、より適切な判断をすることができます。AIの出力結果を検証するプロセスを確立することで、AIの利用に伴うリスクを低減することができます。AIと人間が協力して、より良い意思決定を行うことが重要です。AIの進化とともに、AIの出力結果を検証する技術も進化しています。AIが生成した情報の信頼性を評価するためのツールや手法が開発されており、これらの技術を活用することで、より効率的にAIの出力結果を検証することができます。
プロンプトエンジニアリング
AIへの質問や指示を明確かつ具体的にすることで、ハルシネーションのリスクを低減できます。効果的なプロンプトを作成する技術は、プロンプトエンジニアリングと呼ばれています。プロンプトエンジニアリングとは、AIモデルに対して、より正確で質の高い出力を得るために、質問や指示(プロンプト)を工夫する技術のことです。AIモデルは、プロンプトに含まれる情報に基づいてテキストを生成するため、プロンプトの質が低いと、誤った情報や曖昧な情報を生成する可能性があります。プロンプトエンジニアリングを活用することで、AIモデルのハルシネーションのリスクを低減し、より信頼性の高い情報を得ることができます。
プロンプトを作成する際には、以下の点に注意すると効果的です。
1.質問や指示を明確かつ具体的に記述する
2. 質問の目的や背景を説明する
3. 期待する出力形式を指定する
4.否定的な表現を避け、肯定的な表現を用いる
5.複数の質問をまとめて記述せず、一つずつ記述する
プロンプトエンジニアリングは、AIモデルの性能を最大限に引き出すための重要な技術です。プロンプトエンジニアリングのスキルを身につけることで、AIモデルをより効果的に活用することができます。
まとめ
ハルシネーションと向き合い、AIを安全に活用するために
AIのハルシネーションは、避けて通れない課題です。しかし、その原因と対策を理解することで、リスクを最小限に抑え、AIの恩恵を最大限に享受できます。AIと共存する未来のために、ハルシネーションに関する知識を深め、賢くAIを活用していきましょう。AIは、私たちの生活や仕事をより豊かにする可能性を秘めていますが、同時に、誤った情報や偏った情報に基づいて意思決定を行ってしまうリスクも抱えています。AIのハルシネーションは、そのリスクの代表的な例と言えるでしょう。
AIのハルシネーションと向き合い、AIを安全に活用するためには、以下の3つの点が重要です。
1.AIのハルシネーションに関する知識を深める
2. AIの出力結果を鵜呑みにせず、必ず人間の目で検証する
3.AIの利用目的に合わせて、適切な対策を講じる
AIのハルシネーションに関する知識を深めることで、ハルシネーションのリスクを認識し、適切な対策を講じることができます。AIの出力結果を鵜呑みにせず、必ず人間の目で検証することで、誤った情報に基づいて意思決定を行ってしまうリスクを低減することができます。AIの利用目的に合わせて、適切な対策を講じることで、AIの恩恵を最大限に享受することができます。
AIと共存する未来のために、私たちは、AIのハルシネーションに関する知識を深め、賢くAIを活用していく必要があります。AIは、私たちの生活や仕事をより豊かにする可能性を秘めていますが、その可能性を最大限に引き出すためには、AIのリスクを理解し、適切な対策を講じる必要があるのです。










