

拡散モデルは、近年の画像生成AI技術の発展を支える重要な概念です。この記事では、拡散モデルの基本的な仕組みから、StableDiffusionなどの具体的なサービス、GANやVAEといった関連技術との違いまで、初心者にもわかりやすく解説します。
拡散モデルの基礎知識
拡散モデルとは何か?
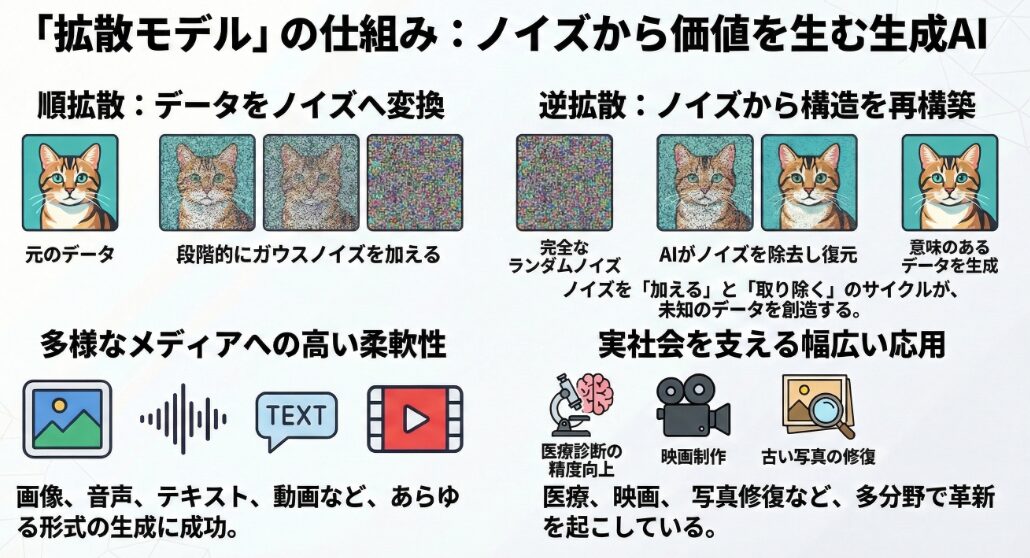
拡散モデルは、深層学習モデルの一種であり、データに徐々にノイズを加えていき、最終的にランダムなノイズに変換する過程(順拡散過程)と、その逆の過程(逆拡散過程)を学習することで、新しいデータを生成します。
このアプローチは、特に画像生成の分野で大きな成功を収めており、従来の生成モデルと比較して、より高品質で多様な画像を生成できることが示されています。
拡散モデルは、画像だけでなく、音声やテキストなどの様々な種類のデータ生成にも応用可能です。その柔軟性と生成能力の高さから、多くの研究者や開発者によって研究が進められています。例えば、画像編集、動画生成、データ補完など、その応用範囲は広がっています。
拡散モデルの登場は、AI技術によるコンテンツ生成の可能性を大きく広げました。従来の手法では難しかった、複雑でリアルなコンテンツの生成が、拡散モデルによって現実のものとなりつつあります。
順拡散過程と逆拡散過程
順拡散過程では、画像などのデータに徐々にノイズを加えていきます。この過程は、元のデータを徐々に破壊していくイメージです。具体的には、ガウスノイズなどのランダムなノイズを、段階的にデータに加えていくことで、最終的にデータは完全にノイズに覆われた状態になります。
一方、逆拡散過程では、このノイズを除去して元の画像を復元するプロセスを学習します。この過程は、順拡散過程とは逆向きに進み、モデルはノイズから徐々に意味のある構造を再構築することを学びます。この逆拡散過程を学習することで、モデルは新しい画像を生成する能力を獲得します。
順拡散過程と逆拡散過程は、拡散モデルの中核となる概念です。順拡散過程でデータをノイズに変換し、逆拡散過程でノイズからデータを再構築するという、一見逆説的なアプローチが、高品質なデータ生成を可能にしています。
拡散モデルの応用例
拡散モデルは、その優れた生成能力から、画像生成以外にも、音声生成、動画生成、データ補完など、様々な分野に応用されています。特に、高品質な画像を生成する能力が注目されており、エンターテイメント、デザイン、医療など、幅広い分野での活用が期待されています。
例えば、医療分野では、拡散モデルを用いて、MRIやCTスキャンの画像を生成し、診断の精度向上に役立てる研究が進められています。また、エンターテイメント分野では、映画やゲームのキャラクターデザインや背景生成に活用され、よりリアルで魅力的なコンテンツの制作に貢献しています。
さらに、拡散モデルは、失われたり破損したデータを補完する用途にも活用できます。例えば、古い写真の修復や、音声データのノイズ除去など、様々なデータ復元タスクに適用可能です。このように、拡散モデルは、様々な分野で革新的な応用が期待される、非常に有望な技術です。
拡散モデルの仕組みを深掘り
ノイズの付加と除去
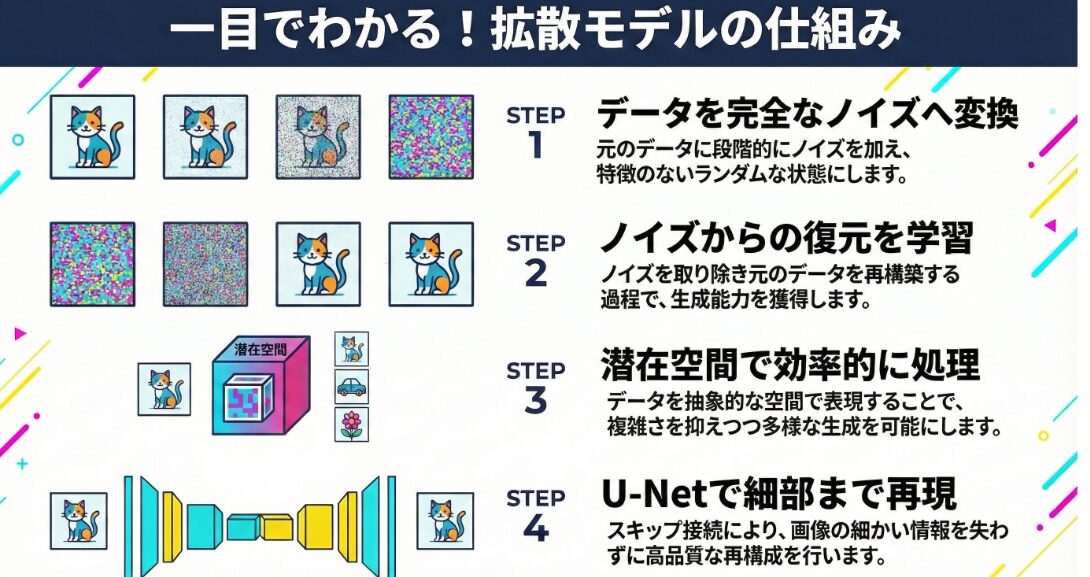
拡散モデルの中核となるプロセスは、データへのノイズの付加と、そのノイズを取り除く過程の学習です。まず、画像などのデータに対して、段階的に微量のノイズを加えていきます。このプロセスを繰り返すことで、最終的にはデータは完全にランダムなノイズに変換されます。
次に、モデルはこのノイズを取り除く過程を学習します。具体的には、ノイズに覆われた状態から、徐々にノイズを取り除き、元のデータを復元するような学習を行います。この学習を通じて、モデルはノイズから意味のある構造を再構築する能力を獲得します。
このノイズの付加と除去のプロセスを繰り返すことで、モデルは様々な種類のノイズに対応できるようになり、高品質なデータを生成することが可能になります。この仕組みが、拡散モデルの優れた生成能力の基盤となっています。
潜在空間での表現
拡散モデルは、データを高次元の潜在空間で表現し、その空間内でノイズの付加と除去を行います。潜在空間とは、データの特徴を抽象的に表現した空間であり、元のデータよりも低次元であることが一般的です。データを潜在空間に変換することで、モデルはデータの複雑さを軽減し、より効率的に学習することができます。
潜在空間内でノイズの付加と除去を行うことで、モデルはデータの多様性を捉え、様々なバリエーションのデータを生成することが可能になります。例えば、顔画像の生成において、潜在空間内で顔の表情や髪型などの特徴を操作することで、様々な顔画像を生成することができます。
潜在空間での表現は、拡散モデルの柔軟性と生成能力を高める上で重要な役割を果たしています。この表現方法により、モデルは高品質で多様なデータを生成することができるのです。
U-Netアーキテクチャ
拡散モデルでは、U-Netと呼ばれる特殊なアーキテクチャがよく用いられます。U-Netは、特に画像セグメンテーションの分野で優れた性能を発揮することで知られていますが、拡散モデルにおいても、高品質な画像生成に貢献しています。
U-Netの主な特徴は、エンコーダとデコーダと呼ばれる2つの部分から構成されている点です。エンコーダは、画像データを多段階に分解し、各段階で特徴を抽出します。一方、デコーダは、エンコーダで抽出された特徴を基に、画像を再構成します。
U-Netでは、エンコーダとデコーダの各段階で、スキップ接続と呼ばれる仕組みが用いられています。スキップ接続は、エンコーダのある段階の特徴量を、デコーダの対応する段階に直接伝える役割を果たします。これにより、画像の細かい部分の情報が失われることなく、より高品質な画像を生成することができます。
U-Netアーキテクチャは、拡散モデルにおける画像生成の精度を高める上で、非常に重要な役割を果たしています。
拡散モデルと他の生成モデルとの違い
GANとの比較
GAN(GenerativeAdversarialNetworks)は、生成器と識別器という2つのニューラルネットワークを競わせることで学習する生成モデルです。生成器は、本物に近いデータを生成するように学習し、識別器は、生成器が生成したデータと本物のデータを区別するように学習します。
拡散モデルと比較して、GANは学習が不安定になりやすいという課題があります。GANの学習は、生成器と識別器のバランスが重要であり、どちらか一方の性能が高すぎると、学習が停滞してしまうことがあります。また、GANは、生成するデータの多様性が低いという課題もあります。
一方、拡散モデルは、GANと比較して、学習が安定しており、より多様なデータを生成することができます。ただし、拡散モデルは、GANよりも計算コストが高いという課題があります。生成される画像の品質はGANも向上していますが、拡散モデルの方がより自然で高品質な画像を生成できる傾向があります。
VAEとの比較
VAE(VariationalAutoencoder)は、データを潜在空間にエンコードし、その潜在空間からデータを再構成する生成モデルです。VAEは、エンコーダとデコーダという2つのニューラルネットワークから構成されており、エンコーダは、データを潜在空間にエンコードし、デコーダは、潜在空間からデータを再構成します。
拡散モデルと比較して、VAEは生成されるデータの品質が低いという課題があります。VAEは、潜在空間にエンコードする際に、データの情報が失われてしまうことがあり、その結果、再構成されるデータの品質が低下してしまうことがあります。
一方、拡散モデルは、VAEと比較して、より高品質なデータを生成することができます。拡散モデルは、ノイズの付加と除去というプロセスを通じて、データの構造をより詳細に学習することができ、その結果、より高品質なデータを生成することができます。VAEは計算コストが低いという利点がありますが、生成される画像の鮮明さやリアリティの面では拡散モデルに劣ります。
Flow-based modelsとの比較
Flow-basedmodelsは、データの確率密度関数を直接学習する生成モデルです。Flow-basedmodelsは、可逆な変換を繰り返すことで、データの分布を単純な分布に変換し、その逆変換を行うことで、新しいデータを生成します。
拡散モデルと比較して、Flow-basedmodelsは計算コストが高いという課題があります。Flow-basedmodelsは、可逆な変換を繰り返す必要があるため、計算量が多くなりがちです。また、Flow-basedmodelsは、複雑なデータの分布を学習することが難しいという課題もあります。
一方、拡散モデルは、Flow-basedmodelsと比較して、計算コストが低く、複雑なデータの分布を学習することができます。ただし、拡散モデルは、Flow-basedmodelsよりも生成されるデータの多様性が低いという課題があります。Flow-basedモデルは理論的には優れた性質を持ちますが、実装や学習の難しさから、拡散モデルほど普及していません。
拡散モデルを活用したAIサービス
Stable Diffusion
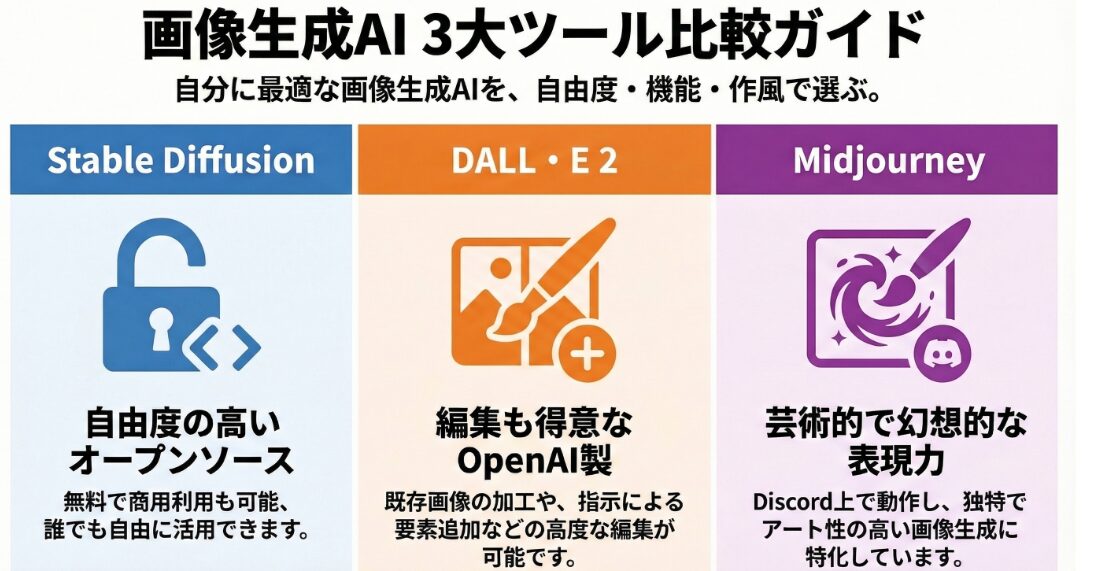
StableDiffusionは、テキストから高品質な画像を生成することができるAIサービスです。ユーザーが入力したテキストに基づいて、AIが自動的に画像を生成します。生成される画像の品質は非常に高く、まるでプロのアーティストが描いたかのような画像を生成することができます。
StableDiffusionは、個人利用から商用利用まで幅広く活用されています。例えば、個人のブログやSNSのアイコン作成、企業の広告デザイン、ゲームのキャラクターデザインなど、様々な用途に利用されています。StableDiffusionは、オープンソースで公開されており、誰でも自由に利用することができます。
StableDiffusionの登場は、AIによる画像生成の可能性を大きく広げました。従来は、専門的な知識や技術が必要だった画像生成が、StableDiffusionによって、誰でも手軽に行えるようになりました。これにより、より多くの人々が、AIによる画像生成の恩恵を受けることができるようになりました。
DALL・E 2
DALL・E2は、OpenAIが開発した画像生成AIサービスです。StableDiffusionと同様に、テキストから高品質な画像を生成することができます。DALL・E 2は、StableDiffusionよりも先に登場し、その高い生成能力で大きな注目を集めました。
DALL・E2は、テキストだけでなく、画像を入力として、画像を編集したり、新しい画像を生成したりすることもできます。例えば、既存の画像にテキストで指示を与えることで、画像のスタイルを変更したり、オブジェクトを追加したりすることができます。
DALL・E2は、商用利用が制限されている場合があります。また、利用にはOpenAIへの登録が必要であり、APIの利用には料金が発生します。DALL・E2は、高度な画像編集機能を提供しており、クリエイティブな用途に幅広く活用されています。
Midjourney
Midjourneyは、Discord上で利用できる画像生成AIサービスです。ユーザーは、Discordのチャット上でテキストを入力することで、AIに画像を生成させることができます。Midjourneyは、アーティスティックな画像を生成することに優れており、独特なスタイルを持った画像を生成することができます。
Midjourneyは、StableDiffusionやDALL・E2と比較して、より抽象的で幻想的な画像を生成する傾向があります。そのため、アート作品やデザインのアイデア出しなど、クリエイティブな用途に適しています。
Midjourneyは、有料サービスであり、無料トライアル期間が設けられています。Midjourneyは、Discordというプラットフォーム上で手軽に利用できるため、多くのユーザーに利用されています。特に、アーティスティックな表現を追求するユーザーからの支持が厚いです。
まとめ
拡散モデルは、画像生成AI技術の発展を支える重要な概念であり、StableDiffusion、DALL・E2、MidjourneyなどのAIサービスを通じて、私たちの生活に浸透しつつあります。これらのサービスは、テキストから画像を生成するだけでなく、画像編集やスタイル変換など、様々な機能を提供しています。
拡散モデルは、従来の生成モデルと比較して、より高品質で多様な画像を生成することができます。そのため、エンターテイメント、デザイン、医療など、幅広い分野での活用が期待されています。画像生成AI技術は、まだ発展途上の段階にありますが、その可能性は計り知れません。
今後も、拡散モデルの技術革新に注目が集まります。より高速で効率的な学習方法の開発、より高品質な画像生成、新たな応用分野の開拓など、様々な研究開発が進められています。拡散モデルは、AI技術によるコンテンツ生成の未来を切り開く、非常に有望な技術です。
これらの技術の進歩は、私たちの創造性を刺激し、新たな表現方法を可能にするでしょう。AIと人間の協調による、より豊かな未来が期待されます。










