

マルチモーダルAIとは?生成AIとの根本的な違い
多様な情報を統合するAI
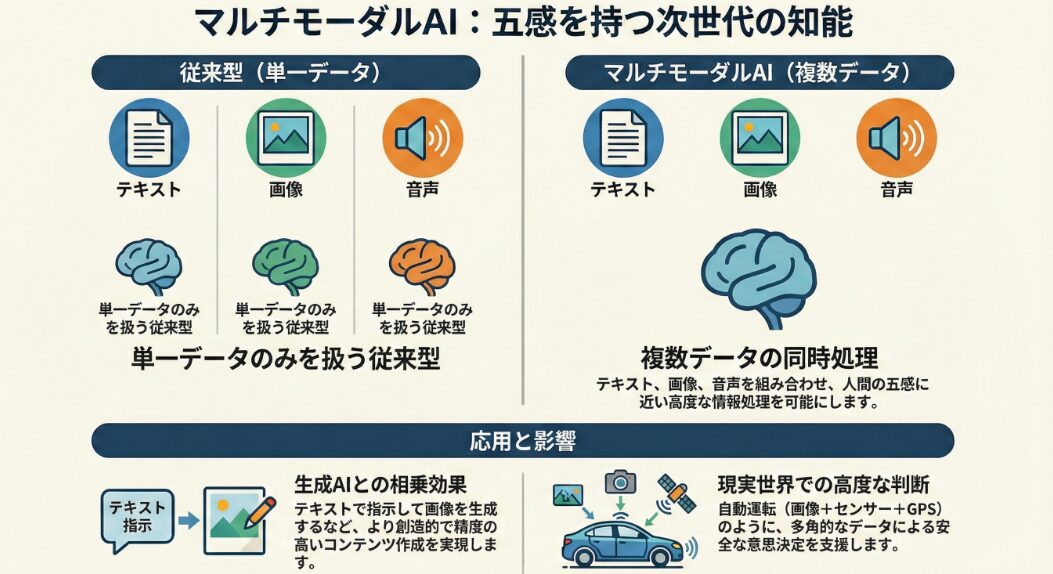
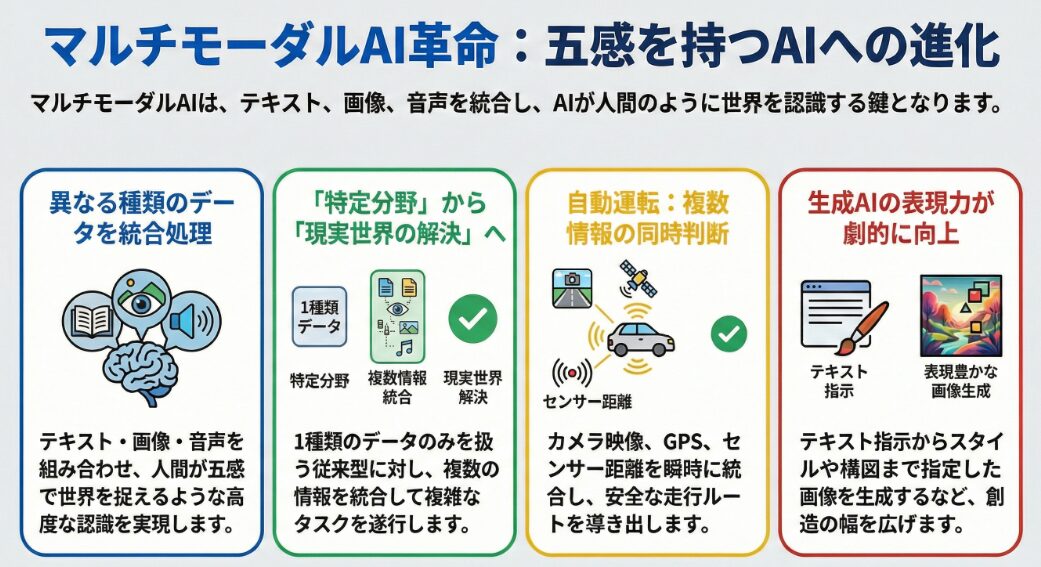
マルチモーダルAIは、テキスト、画像、音声、動画など、複数の異なる種類のデータを組み合わせて処理できるAIです。これにより、人間が五感を使って世界を認識するのに近い、より高度な情報処理が可能になります。
一方、生成AIは、学習したデータに基づいて新しいコンテンツを生成するAIであり、テキスト生成、画像生成、音楽生成など、さまざまな分野で活用されています。
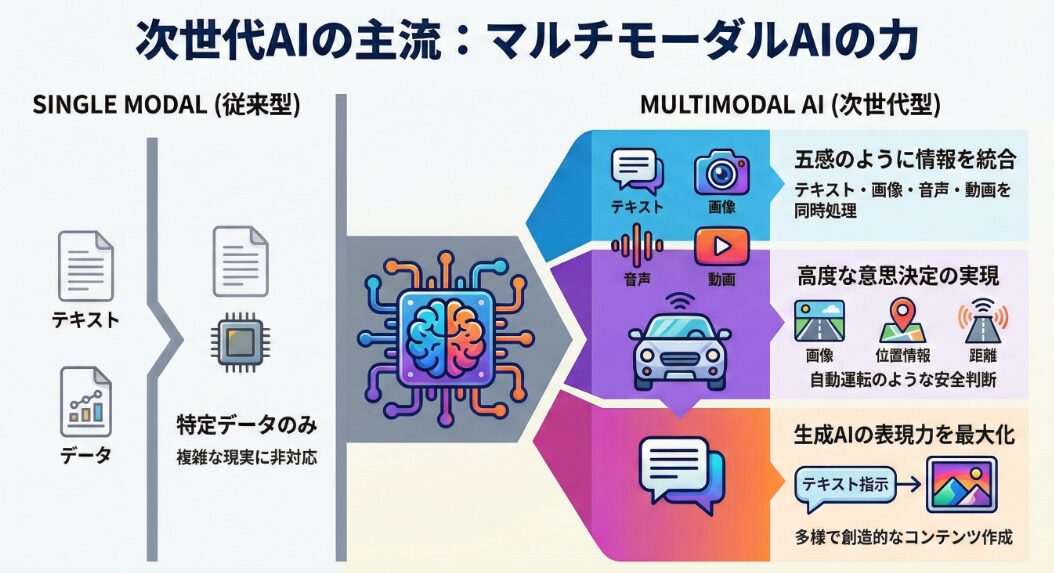
マルチモーダルAIは、情報を統合することで、より複雑で現実世界に近いタスクを遂行できます。例えば、自動運転システムでは、カメラからの画像データ、センサーからの距離データ、GPSからの位置情報などを組み合わせて、安全な運転を実現します。このように、複数の情報を統合することで、AIはより高度な判断を下すことができるのです。
シングルモーダルAIとの比較
従来のシングルモーダルAIは、特定の種類のデータ(例えば、テキストのみ、画像のみ)しか処理できませんでした。マルチモーダルAIは、複数のデータを組み合わせることで、より複雑なタスクに対応できます。
シングルモーダルAIは、特定のタスクに特化しているため、その分野においては高い精度を発揮できます。しかし、現実世界は複数の情報が複雑に絡み合っているため、シングルモーダルAIだけでは対応できない場面が多く存在します。
マルチモーダルAIは、複数の情報を統合することで、より柔軟で汎用的なタスクに対応できます。例えば、画像認識AIに音声認識AIを組み合わせることで、画像の内容を説明するテキストを自動生成することができます。
生成AIにおけるマルチモーダル活用の現状
近年では、生成AIにおいてもマルチモーダルなアプローチが取り入れられています。例えば、テキストと画像を組み合わせて新しい画像を生成したり、音声とテキストから感情を分析したりするなど、より高度な表現や分析が可能になっています。
従来の生成AIは、特定の種類のデータに基づいてコンテンツを生成するため、表現の幅が限られていました。しかし、マルチモーダルなアプローチを取り入れることで、より多様で創造的なコンテンツを生成することが可能になります。
例えば、テキストで指示を与え、それに基づいて画像を生成するAIでは、テキストの内容だけでなく、画像のスタイルや構図なども指定することができます。これにより、ユーザーはより自由な発想でコンテンツを生成することができます。
マルチモーダルAIで何ができる?具体的な活用事例
より自然な対話システムの構築
テキストだけでなく、表情や声のトーンも考慮することで、より人間らしい自然な対話が可能なAIアシスタントやチャットボットが実現できます。
従来のチャットボットは、テキストのみに基づいて応答するため、人間のような感情やニュアンスを理解することができませんでした。しかし、マルチモーダルAIを活用することで、チャットボットはユーザーの表情や声のトーンを読み取り、より適切な応答をすることができます。
例えば、ユーザーが悲しい声で質問した場合、チャットボットは同情的な言葉を返すことができます。また、ユーザーが笑顔で話している場合、チャットボットはより友好的な言葉を返すことができます。
高度な異常検知とセキュリティ
カメラ映像と音声データを組み合わせることで、不審な行動や異常な事態をより正確に検知し、セキュリティを向上させることができます。
従来のセキュリティシステムは、カメラ映像のみに基づいて異常を検知するため、誤検知が多く発生していました。しかし、マルチモーダルAIを活用することで、カメラ映像と音声データを組み合わせ、より正確に異常を検知することができます。
例えば、カメラ映像で人が倒れていることを検知し、同時に悲鳴や助けを求める声が聞こえた場合、緊急事態である可能性が高いと判断できます。これにより、迅速な対応が可能になり、被害を最小限に抑えることができます。
医療分野での応用
画像診断と患者の問診記録を組み合わせることで、病気の早期発見や診断精度向上に貢献できます。
従来の画像診断は、医師の経験や知識に基づいて行われるため、診断にばらつきが生じる可能性がありました。しかし、マルチモーダルAIを活用することで、画像診断と患者の問診記録を組み合わせ、より客観的で正確な診断を行うことができます。
例えば、レントゲン画像で肺に異常が見られた場合、患者の喫煙歴や呼吸器系の病歴を考慮することで、肺がんである可能性が高いと判断できます。これにより、早期発見につながり、治療の成功率を高めることができます。
マルチモーダルAIの課題と今後の展望
データ処理の複雑さとコスト
異なる種類のデータを組み合わせるため、データ処理が複雑になり、計算コストも高くなる傾向があります。効率的なデータ処理技術の開発が求められます。
マルチモーダルAIは、テキスト、画像、音声など、異なる種類のデータを同時に処理するため、データ形式の変換や統合、同期などの複雑な処理が必要になります。これらの処理には、高度な計算能力が必要となり、計算コストが高くなる傾向があります。
今後の展望としては、データ処理の効率化や計算コストの削減が重要な課題となります。新しいアルゴリズムの開発や、GPUなどの高性能なハードウェアの活用などが期待されます。
倫理的な問題とバイアス
学習データに偏りがある場合、AIの判断にバイアスが生じる可能性があります。倫理的な問題に対する考慮と、公平性を担保するための技術開発が必要です。
マルチモーダルAIは、大量の学習データに基づいて学習するため、学習データに偏りがある場合、AIの判断にバイアスが生じる可能性があります。例えば、特定の性別や人種に関するデータが偏って学習された場合、AIはその性別や人種に対して差別的な判断をする可能性があります。
今後の展望としては、倫理的な問題に対する考慮と、公平性を担保するための技術開発が重要となります。学習データの偏りを是正したり、AIの判断プロセスを透明化したりするなどの対策が求められます。
Google Geminiがもたらす可能性
GoogleのGeminiは、テキスト、画像、音声、動画など、様々な情報を統合的に扱える最先端のマルチモーダルAIモデルです。Geminiの登場により、より高度なAIアプリケーションの開発が加速すると期待されています。VertexAIでの活用も注目されています。
Geminiは、Googleが長年培ってきたAI技術の粋を集めたものであり、従来のAIモデルと比較して、より高度な情報処理能力と表現力を備えています。例えば、Geminiは、テキストで指示を与えられただけで、高品質な画像を生成することができます。また、Geminiは、音声とテキストを組み合わせて、より自然な対話を行うことができます。
Geminiの登場により、AIは私たちの生活やビジネスに、より深く浸透していくことが予想されます。
まとめ
マルチモーダルAIは、複数の情報を組み合わせることで、より高度なタスクをこなせる可能性を秘めています。生成AIとの組み合わせにより、その可能性はさらに広がります。GoogleのGeminiをはじめとする最新技術の動向に注目し、ビジネスや社会への活用を検討していくことが重要です。
マルチモーダルAIは、まだ発展途上の技術であり、課題も多く存在します。しかし、その潜在能力は非常に高く、今後の技術革新によって、私たちの生活やビジネスに大きな変革をもたらすことが期待されます。
私たちは、マルチモーダルAIの可能性を理解し、その技術を適切に活用することで、より豊かで持続可能な社会を実現していくことができるでしょう。AI技術の進化に常にアンテナを張り、その可能性を最大限に引き出すための努力を続けることが重要です。










