
RAG(検索拡張生成)は、生成AIの精度と信頼性を高めるための重要な技術です。この記事では、RAGの仕組み、活用例、精度向上のためのノウハウについてわかりやすく解説します。ビジネスにおける生成AIの可能性を最大限に引き出すために、RAGの知識を深めましょう。
RAG(検索拡張生成)とは?
RAGの基本的な仕組み
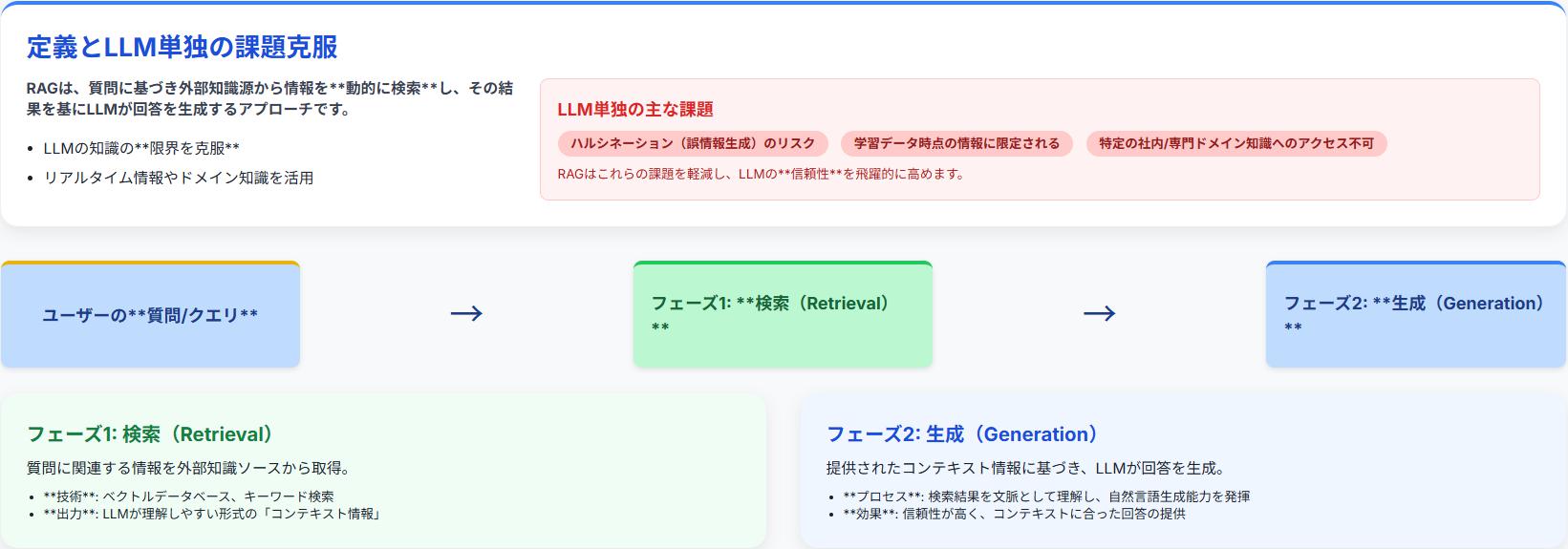
RAG(Retrieval-AugmentedGeneration、検索拡張生成)は、生成AIの精度を飛躍的に向上させるための革新的なアプローチです。大規模言語モデル(LLM)単独では、学習データに含まれる情報に基づいて回答を生成しますが、RAGは、LLMが持つ知識の限界を克服し、リアルタイムの情報や特定のドメイン知識を活用できるようにします。具体的には、質問やプロンプトに基づいて、外部の知識源から関連情報を動的に検索し、その検索結果を基にLLMが回答を生成します。
この仕組みにより、LLMは常に最新の情報に基づいた、より正確でコンテキストに即した回答を提供できるようになります。RAGは、事実に基づかない誤った情報を生成する「ハルシネーション」のリスクを軽減し、生成AIの信頼性を高める上で重要な役割を果たします。RAGは、情報検索と自然言語生成という2つの技術を組み合わせることで、より高度な情報処理と知識生成を実現します。
RAGの主要なコンポーネント
RAGは、主に2つの重要なフェーズで構成されています。それは、検索フェーズと生成フェーズです。検索フェーズでは、ユーザーからの質問やクエリを受け取り、それに関連する情報を外部の知識ソースから効率的に取得します。この際、ベクトルデータベースやキーワード検索など、様々な情報検索技術が活用されます。検索された情報は、LLMが理解しやすい形式に変換され、次の生成フェーズに渡されます。
生成フェーズでは、検索フェーズで取得した情報を基に、LLMが回答を生成します。LLMは、検索された情報を文脈として理解し、質問に対する適切な回答を生成します。このプロセスにおいて、LLMは高度な自然言語生成能力を発揮し、人間が理解しやすい自然な文章で回答を生成します。検索フェーズと生成フェーズが連携することで、RAGは質問に対して的確かつ詳細な回答を提供することが可能になります。
RAGとLLMの連携
RAGは、LLM(大規模言語モデル)が単独ではアクセスできない、最新の情報や特定の専門分野の知識を提供することで、その回答精度を大幅に向上させます。LLMは、学習データに基づいて情報を生成するため、学習データに含まれていない情報や、学習後に更新された情報については対応できません。RAGは、外部の知識ソースから必要な情報を検索し、LLMに提供することで、この問題を解決します。
具体的には、RAGは、LLMに対して、質問に対する回答を生成するために必要なコンテキスト情報を提供します。LLMは、RAGから提供された情報を基に、より信頼性が高く、コンテキストに合った回答を生成することができます。この連携により、LLMは、単なる知識の暗記ではなく、知識を活用して問題を解決する能力を高めることができます。RAGは、LLMの潜在能力を最大限に引き出すための重要な技術と言えるでしょう。
RAGの活用例

社内FAQの自動応答
RAGを活用することで、社内のFAQデータベースから従業員の質問に関連する情報を迅速に検索し、自動で回答を生成することが可能になります。従来のFAQシステムでは、質問に対する回答が事前に登録されたものに限られていましたが、RAGは、質問の内容に応じて動的に情報を検索し、より的確な回答を提供することができます。
これにより、従業員は必要な情報を迅速に入手できるようになり、自己解決を促進することができます。また、ヘルプデスクの担当者は、RAGが自動で回答できない複雑な質問に集中できるようになり、業務効率が大幅に向上します。RAGは、社内FAQの自動応答を高度化し、従業員の生産性向上に貢献する強力なツールとなります。RAGの導入により、従業員満足度の向上も期待できます。
顧客対応の効率化
RAGは、顧客からの問い合わせ内容に応じて、関連する製品情報、サポート情報、FAQなどをリアルタイムで提供することで、顧客対応を劇的に効率化します。従来の顧客対応では、オペレーターが手動で情報を検索する必要がありましたが、RAGは、問い合わせ内容を解析し、自動的に関連情報を提示することで、オペレーターの負担を軽減します。
オペレーターは、RAGが提供する情報を基に、迅速かつ正確な回答を顧客に提供することができます。これにより、顧客満足度が向上し、顧客ロイヤルティの強化にも繋がります。さらに、RAGは、顧客対応履歴を分析し、よくある質問や問題点を特定することで、FAQの改善や製品改善にも役立ちます。RAGは、顧客対応の品質向上と効率化を同時に実現する、強力なソリューションです。
研究開発の支援
RAGは、研究論文、特許情報、技術ドキュメントなど、膨大な専門知識データベースから、研究テーマに関連する情報を迅速かつ網羅的に検索し、研究者の情報収集を強力に支援します。従来の研究者は、手作業で文献を検索し、情報を整理する必要がありましたが、RAGは、高度な検索技術と自然言語処理技術を組み合わせることで、このプロセスを自動化します。
研究者は、RAGが提供する情報を基に、最新の研究動向を把握し、新たな研究アイデアを発想することができます。また、RAGは、研究論文の執筆や特許申請の準備にも役立ちます。RAGは、研究開発の加速と効率化に貢献する、不可欠なツールとなりつつあります。RAGを活用することで、研究者はより創造的な活動に集中できるようになり、革新的な成果を生み出す可能性が高まります。
RAGの精度を高めるためのポイント

検索クエリの最適化
RAGの精度を最大限に引き出すためには、検索クエリを最適化し、質問や要求に対して最も関連性の高い情報を効率的に取得することが不可欠です。不適切な検索クエリは、ノイズの多い情報や無関係な結果を招き、LLMの回答精度を低下させる可能性があります。効果的な検索クエリの最適化には、いくつかの重要な側面があります。
まず、キーワードの選定が重要です。質問や要求の本質を捉え、適切なキーワードを選択することで、検索エンジンはより関連性の高い情報を特定できます。次に、検索エンジンの設定を調整することも重要です。検索範囲を絞り込んだり、特定の情報源を優先したりすることで、検索結果の精度を高めることができます。さらに、自然言語処理技術を活用して、質問の意図をより深く理解し、それに基づいて検索クエリを自動的に生成することも有効です。
ベクトルデータベースの活用
ベクトルデータベースは、テキストデータや画像データなどの非構造化データを、意味的な類似性に基づいてベクトル形式で保存し、高速かつ高精度な検索を実現するデータベースです。RAGにベクトルデータベースを活用することで、従来のキーワード検索では難しかった、意味的に関連性の高い情報を効率的に取得することができます。ベクトルデータベースは、テキストデータを数値ベクトルに変換し、ベクトル空間上で類似度を計算することで、意味的に近い情報を検索します。
これにより、キーワードが一致しなくても、質問の内容と意味的に関連する情報を取得することが可能になります。例えば、「猫」に関する質問に対して、「ネコ科の動物」や「ペット」といった関連情報を取得することができます。RAGにベクトルデータベースを活用することで、LLMはより高度な推論を行い、より正確でコンテキストに合った回答を生成することができます。
データの品質管理
RAGの精度は、基盤となるデータの品質に大きく依存します。データの品質が低いと、RAGは不正確な情報や誤った情報を生成する可能性があり、その結果、LLMの回答の信頼性が損なわれます。したがって、RAGの精度を維持・向上させるためには、データの品質管理が不可欠です。データの品質管理には、いくつかの重要な側面があります。
まず、データの正確性を確保することが重要です。データが誤っている場合、RAGは誤った情報に基づいて回答を生成する可能性があります。次に、データの網羅性を確保することが重要です。データが不足している場合、RAGは質問に対して十分な情報を提供できない可能性があります。さらに、データの最新性を維持することが重要です。データが古くなっている場合、RAGは最新の情報に基づいて回答を生成できません。
RAG導入における注意点

セキュリティの確保
RAGを導入する際には、セキュリティ対策を最優先事項として考慮する必要があります。特に、機密情報や個人情報を含むデータを扱う場合には、情報漏洩や不正アクセスなどのリスクを最小限に抑えるための厳格な対策が不可欠です。アクセス制御、暗号化、データマスキングなどの技術を適切に組み合わせることで、データの安全性を確保する必要があります。
アクセス制御は、特定のユーザーやグループのみが機密データにアクセスできるように制限するメカニズムです。暗号化は、データを暗号化された形式に変換することで、不正なアクセスから保護します。データマスキングは、機密データを別の値に置き換えることで、データの機密性を維持しながら、開発やテストなどの目的でデータを使用できるようにします。RAGのアーキテクチャ全体にわたって、これらのセキュリティ対策を実装することが重要です。
コストの最適化
RAGの導入と運用には、インフラストラクチャのコスト、データストレージのコスト、APIの使用コストなど、さまざまなコストが発生します。これらのコストを最適化するために、いくつかの戦略を検討する必要があります。クラウドサービスの活用は、コスト効率の高いインフラストラクチャを提供する上で有効な選択肢です。クラウドサービスは、必要なリソースをオンデマンドで提供し、使用量に基づいて料金を支払うことができるため、初期投資を抑え、柔軟なスケーリングを実現できます。
データ圧縮技術は、データストレージのコストを削減するために役立ちます。データを圧縮することで、必要なストレージ容量を減らし、ストレージコストを削減できます。APIの使用コストを最適化するために、APIの使用頻度を減らしたり、より効率的なAPIエンドポイントを選択したりすることができます。
継続的な改善
RAGは、一度導入したら終わりではありません。ユーザーからのフィードバックを定期的に収集し、そのフィードバックを基に検索クエリの改善、データソースの追加、アルゴリズムの調整などを行うことで、RAGの精度と利便性を継続的に向上させていく必要があります。ユーザーフィードバックは、RAGの改善にとって非常に貴重な情報源です。
ユーザーがどのような情報を求めているのか、RAGが提供する情報がどのように役立っているのか、どのような点が改善できるのかなど、ユーザーの視点からRAGの課題を把握することができます。A/Bテストは、異なる検索クエリやアルゴリズムを比較し、より効果的なものを特定するために役立ちます。定期的な評価を通じて、RAGのパフォーマンスを客観的に評価し、改善の方向性を定めることが重要です。
まとめ
RAG(検索拡張生成)は、生成AIの可能性を最大限に引き出すための鍵となる技術です。大規模言語モデル(LLM)が持つ知識の限界を補い、リアルタイムの情報や特定のドメイン知識を活用することで、RAGはより正確で信頼性の高い回答を生成することを可能にします。RAGの仕組みを深く理解し、適切な活用方法を選択することで、ビジネスにおける生成AIの潜在能力を最大限に引き出すことができます。
社内FAQの自動応答、顧客対応の効率化、研究開発の支援など、様々な分野でRAGは活用されており、その効果は実証されています。AlliLLMAppMarketや活文などのソリューションを参考に、自社のニーズに最適なRAGを導入し、生成AIの恩恵を享受しましょう。RAGは、単なる技術的なツールではなく、ビジネスの成長を加速させるための戦略的な資産となるでしょう。










